
ELF 三视图
同一个 ELF 文件,需要从三个不同的视角去理解。这三个视角分别是:
- 文件视图
- 内存视图
- 动态链接视图
文件视图回答“这个 ELF 在磁盘里怎么组织”;内存视图回答“这个 ELF 被加载后怎么摆放”;动态链接视图回答“这个 ELF 运行时怎么和外部库协作”。三者看的是同一个文件,但解决的是三类完全不同的问题。
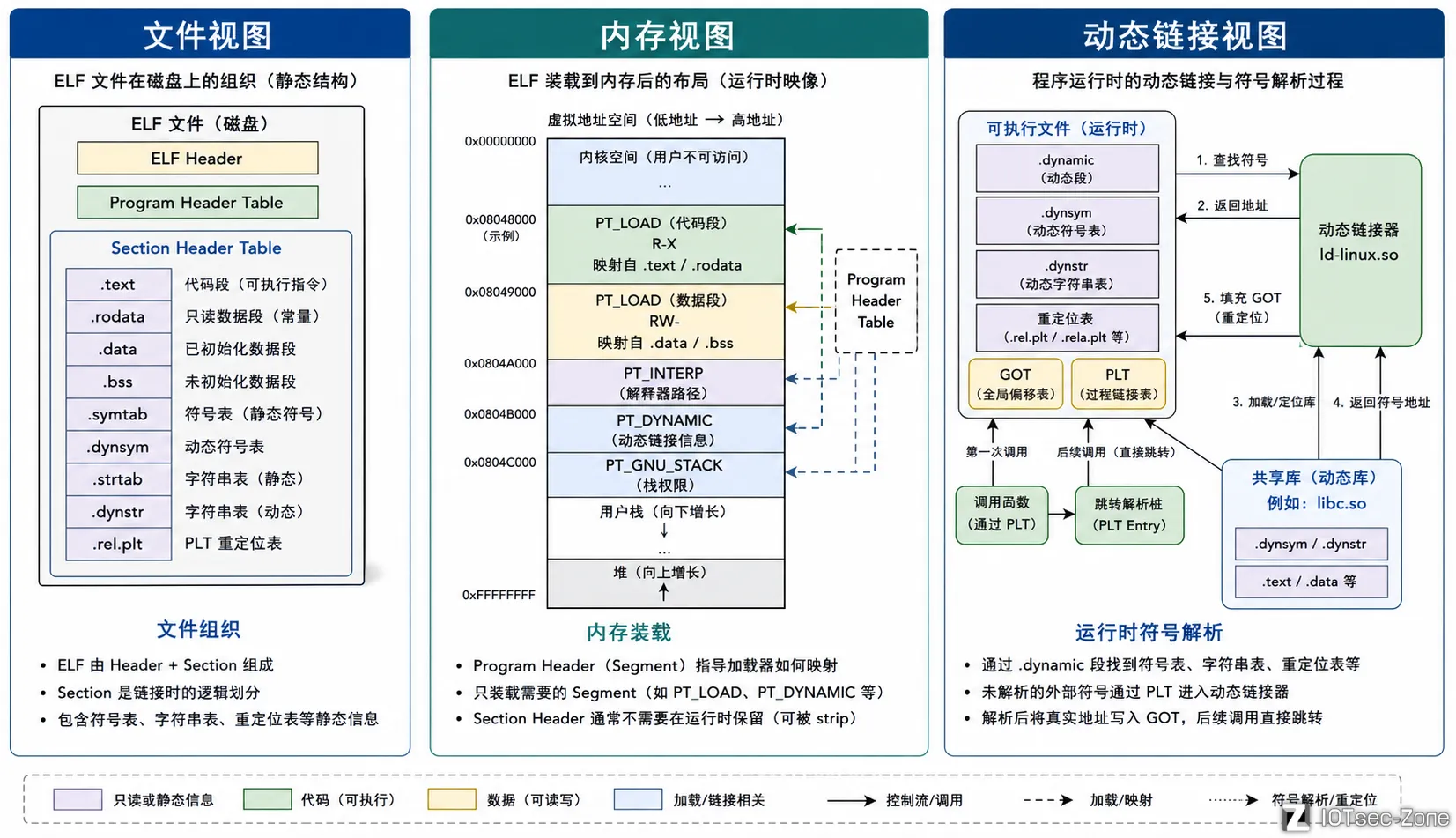
文件视图
文件视图关心的是:ELF 在文件里是怎么存的。
这个视角下最重要的对象是 Section Header Table (节头表)和各类 section。
常见 section 包括:
.text:程序代码.rodata:只读常量.data:已初始化全局变量.bss:未初始化全局变量.symtab/.dynsym:符号表.strtab/.dynstr:字符串表.rel.*/.rela.*:重定位表
文件视图特别适合查看:这个 ELF 里有哪些 section,某个 section 在文件中的偏移是多少,符号表、字符串表、重定位表分别放在哪里,strip 前后文件内部结构发生了什么变化。也就是我们使用IDA,objump的视角。它重点让我们认识某个数据在文件中是属于什么类别
文件视图的核心结构是:ELF Header:总导航,我们节头表在哪Section Header Table:节目录- 各类 section:真实承载代码、数据、符号、字符串等内容
内存视图
内存视图关心的是:程序运行时,ELF 被加载器怎么映射到内存中。
这个视角下最重要的对象是 Program Header Table
常见的程序头项包括:
PT_LOAD:可装载段PT_INTERP:动态链接器路径PT_DYNAMIC:动态链接所需信息PT_NOTE:附加说明信息PT_GNU_STACK:栈权限PT_GNU_RELRO:重定位后只读区域
内存视图是 ELF 被加载执行时的视角,主要帮助加载器理解文件中哪些区域要映射到进程虚拟内存。它的核心索引是程序头表,程序头表中的每个程序头项描述一个 segment,例如PT_LOAD段会被映射到内存中,并带有虚拟地址、文件偏移、内存大小和读写执行权限。
内存视图的核心结构:ELF Header:给出程序头表位置Program Header Table:程序头表- 各类 segment:真正参与装载的内存块
动态链接视图
动态链接视图关心的是:程序运行时如何解析外部符号、如何连接共享库、如何修正地址。
这个视角下最重要的对象包括:
Dynamic Segment动态段Dynamic Symbol Table动态符号表Relocation重定位表GOT全局偏移表 存放真实函数地址的数据表PLT过程链接表 调用外部函数时的跳板代码
动态链接视图是 ELF 在运行时与共享库协作的视角,主要帮助动态链接器理解程序依赖哪些外部库、哪些符号需要解析、哪些地址需要重定位。它的核心索引是动态段.dynamic,动态段中的各项会描述动态符号表、字符串表、重定位表、GOT、PLT 以及依赖的共享库等信息,使动态链接器能够在程序运行时完成外部函数地址解析与跳转。
动态链接视图的核心结构PT_INTERP:指定动态链接器路径PT_DYNAMIC/.dynamic:动态链接说明书.dynsym/.dynstr:动态符号和字符串.rel.*/.rela.*:重定位.got/.plt:运行时跳转与延迟绑定
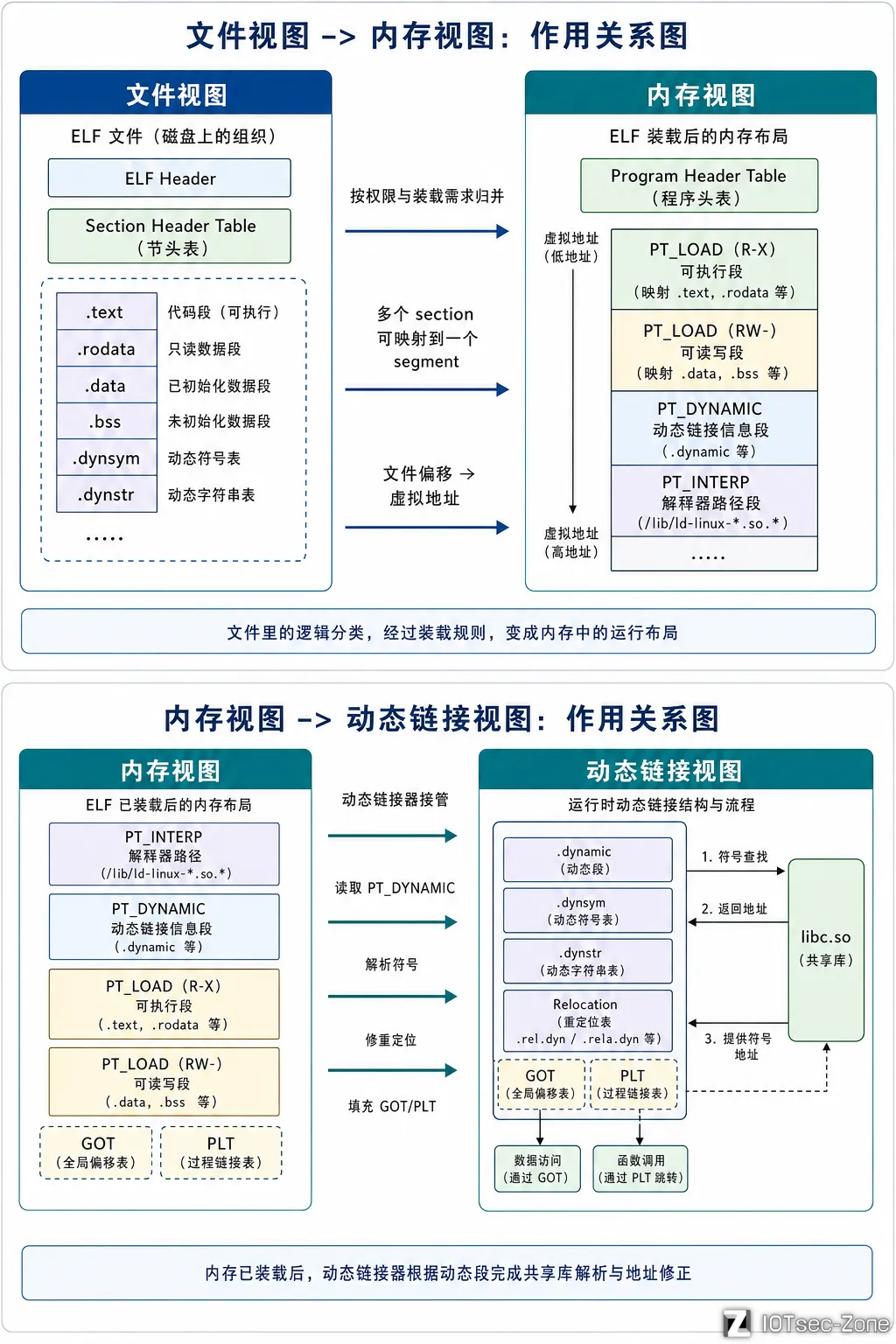
三个视图间的运作关系
这三个视图不是孤立的,它们是一层一层衔接起来的。
最上层的入口是 ELF Header。它先告诉我们:
- 文件是不是 ELF
- 是 32 位还是 64 位
- 是小端还是大端
- 程序头表在哪
- 节头表在哪
接下来: - 如果我们顺着
e_shoff去读,就进入 文件视图 - 如果我们顺着
e_phoff去读,就进入 内存视图 - 如果我们在程序头表里继续找到
PT_DYNAMIC和PT_INTERP,就进入 动态链接视图
三视图之间的关系并不是“互相竞争”,而是“互相接力”:
ELF Header负责总导航Section Header Table负责解释文件内部怎么分类Program Header Table负责解释文件如何被装进内存Dynamic Segment负责解释程序如何在运行时完成动态链接
换句话说,文件视图时静态结构图,内存视图是运行时布局图,动态链接视图是运行时协作图。
ELF Header
ELF Header就是ELF文件开头的一小段“总控表”
我们后面要解析 Program Header、Section Header、动态段,第一步都要靠它给出的偏移和数量去定位。
ELF文件已经在elf.h共享库文件里面定义[[Linux文件结构#usr#include]]
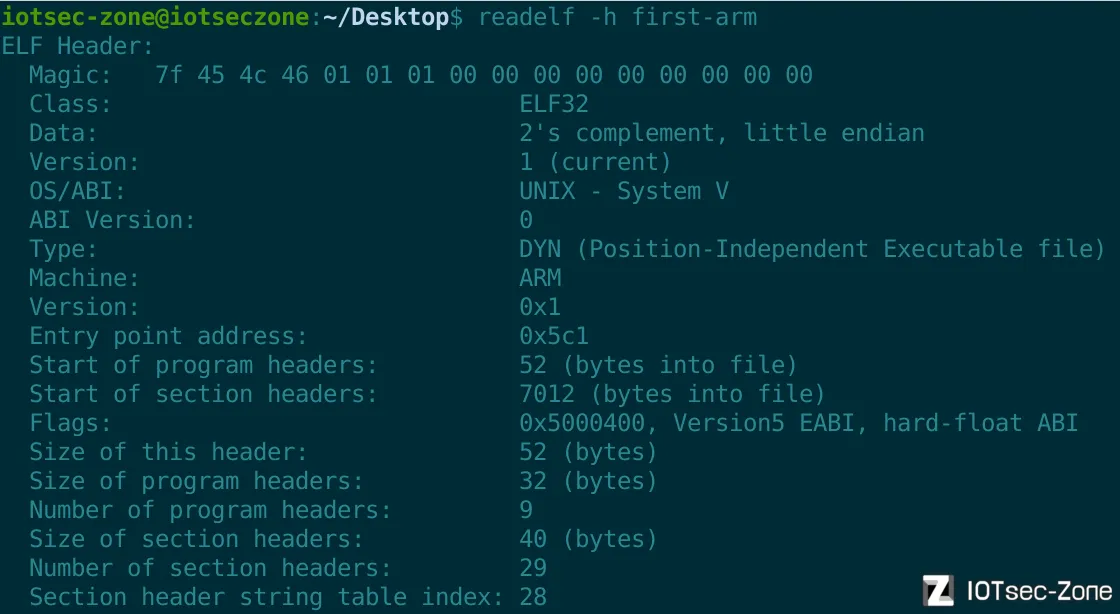
readelf -h first-arm查看文件ELF Header
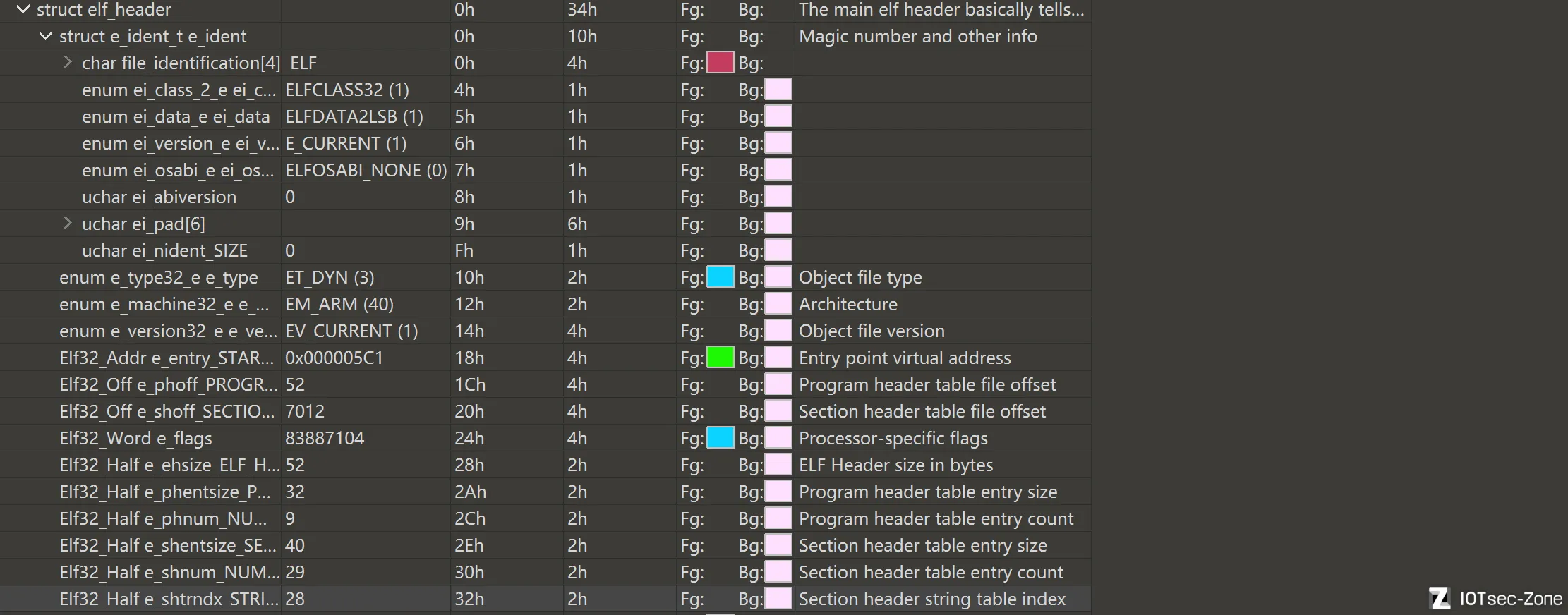
我们在010editor里面开启ELF.bat模板,查看二进制文件的结构树
[!tip]
Addr 表示地址,也就是虚拟地址
在ELF里:
Elf32_Addr是 4字节Elf64_Addr是 8字节
常见字段:e_entrysh_addrp_vaddr
它的含义是: 程序装载到内存后,这个东西在内存中的地址是多少。Off 表示偏移,通常指文件偏移
在ELF里:
Elf32_off是 4字节Elf64_off是 8字节
常见字段:e_phoffe_shoffp_offsetsh_offset它的含义是:
这个结构或数据在ELF文件里的位置是多少
Half 表示 半字,通常是 2 字节
在 ELF 里一般对应:
-Elf32_Half
-Elf64_Half
底层通常就是:
uint16_t
常用来表示:- 类型编号
- 数量
- 索引
- 小范围标志值
Word表示字,通常是
4字节
在ELF里一般对应:
Elf32_WordElf64_Word
底层通常是:uint32_t
常用来表示:- 标志
- 计数
- 版本
- section类型等
e_ident
Magic
e_ident[EI_MAG0~EI_MAG3]
该字段是 ELF 文件的魔数标识,固定为 0x7F 'E' 'L' 'F',用于告诉加载器和分析工具“这就是一个 ELF 文件”。 如果这 4 个字节不对,系统和逆向工具通常都会直接认为它不是合法 ELF。
图中对应的是:
- file_identification[0] = 0x7F
- file_identification[1] = 'E'
- file_identification[2] = 'L'
- file_identification[3] = 'F'
Class
e_ident[EI_CLASS]
该字节用于标识 ELF 的位数类型,也就是这是 32 位 ELF 还是 64 位 ELF。
常见取值: - ELFCLASS32 (1):32 位
- ELFCLASS64 (2):64 位
Data
e_ident[EI_DATA]
该字节用于标识 ELF 文件采用的数据编码方式,也就是大小端序。
常见取值: - ELFDATA2LSB (1):小端
- ELFDATA2MSB (2):大端
Version
e_ident[EI_VERSION]
该字节用于标识 ELF 文件头版本,通常应为: - EV_CURRENT / E_CURRENT (1)
它表示当前使用的是 ELF 的标准版本。 正常 ELF 文件这里一般都是 1,如果该字段不是当前版本值,加载器或分析工具可能会认为该 ELF 头不规范或存在异常。
OS/ABI
e_ident[EI_OSABI]
该字节用于标识 ELF 文件面向的目标 ABI / 操作系统环境。
常见取值包括: - ELFOSABI_NONE (0):通常表示 System V / 通用默认 ABI
- 也可能见到 Linux、FreeBSD 等其他 ABI 标识
在很多 Android 和 Linux 场景下,这个字段即使是 0 也完全正常,因为很多工具链默认就写成 ELFOSABI_NONE。 它更多是“说明目标 ABI 环境”的辅助信息,而不是决定文件能不能运行的唯一依据。
ABIVersion
e_ident[EI_ABIVERSION]
该字节用于标识 ABI 的具体版本号。 如果 OSABI 没有特别指定复杂 ABI,这里通常就是 0。
在大多数普通 ELF 分析中,这个字段存在感不高,但它仍属于 ELF 身份信息的一部分。
Pad
e_ident[EI_PAD]
这是保留填充字段,用来把 e_ident 补齐到固定长度。 这些字节通常都是 0,主要作用是保留扩展空间和保持结构对齐。 它本身一般不承载实际业务语义,但如果这里出现异常值,有时也可以作为样本是否被篡改的辅助参考。
**Nident
e_ident[EI_NIDENT]
EI_NIDENT 更常表示 e_ident 这个数组的总长度常量,标准大小是 16 字节。
e_ident 整体就是 ELF 头最前面的 16 字节身份信息区。
它包含了前面整体
e_type
该字段用于标识 ELF 文件的目标文件类型,也就是这个 ELF 到底是可重定位文件、可执行文件、共享库还是核心转储文件。
常见取值:
- ET_REL:可重定位文件,通常是 .o
- ET_EXEC:可执行文件
- ET_DYN:共享对象文件,常见于 .so,也可能是 PIE 可执行文件
- ET_CORE:核心转储文件
在现代 Linux / Android 环境下,很多开启了 PIE 的可执行文件在头里也会显示成 ET_DYN,所以看到 ET_DYN 不一定就代表它一定是传统意义上的 .so 动态库,还要结合程序头、入口点和装载方式一起分析。
e_machine
该字段用于标识 ELF 面向的目标架构,也就是 CPU 指令集类型。
常见取值:
- EM_386:x86
- EM_X86_64:x86_64
- EM_ARM:32 位 ARM
- EM_AARCH64:64 位 ARM
- EM_MIPS:MIPS
e_version
该字段用于标识 ELF 文件版本,通常应为:
- EV_CURRENT (1)
它和前面的 e_ident[EI_VERSION] 类似,都是说明当前 ELF 使用的是标准定义的当前版本。
正常情况下这里几乎总是 1。
如果该字段不是标准值,通常意味着这个 ELF 文件头可能被破坏、伪造,或者不符合常规规范。
e_entry
该字段表示 ELF 文件的入口点虚拟地址,也就是程序开始执行时第一条指令所在的位置。
图中该字段的值是:0x000005C1
对于可执行文件或可装载对象来说,这个值很关键,因为它告诉加载器“程序应该从哪里开始跑”。
e_phoff
该字段表示 程序头表 Program Header Table 在文件中的偏移。
图中该字段的值是:52,也就是说,从文件开头偏移 52 字节的位置开始,就是程序头表。
e_shoff
该字段表示 节头表 Section Header Table 在文件中的偏移。
图中该字段的值是:7012,也就是说,从文件开头偏移 7012 字节的位置开始,就是节头表。
e_flags
该字段表示 处理器相关标志位。
图中该字段的值是:
- 83887104
这个字段的具体含义依赖于目标架构。
也就是说,在 ARM、MIPS、RISC-V 等不同架构下,e_flags 的解释方法不一样。
在 ARM ELF 中,它常常携带一些与 ABI、浮点、指令集特性相关的信息。
因此分析时不能只看十进制值本身,而要结合对应架构规范进一步拆解。
e_ehsize
该字段表示 ELF Header 本身的大小,单位是字节。
图中该字段的值是:52,这说明这个 ELF 文件头长度是 52 字节。
对于 32 位 ELF 来说,这个值通常就是常见的标准大小。
它的作用是明确告诉解析器:ELF 头到这里结束,后面的结构从哪里开始继续读。
e_phentsize
该字段表示 每个程序头表项的大小,单位是字节。
图中该字段的值是:32也就是说,程序头表中每一个 Program Header Entry 占 32 字节。
有了这个值,再配合 e_phnum,就能算出整个程序头表的总大小。
e_phnum
该字段表示 程序头表项的数量。
图中该字段的值是:
- 9
这意味着当前 ELF 一共有 9 个程序头项。
程序头项通常包括: - PT_LOAD
- PT_DYNAMIC
- PT_INTERP
- PT_NOTE
- PT_GNU_STACK
这些项决定了程序如何被装载进内存,因此 e_phnum 直接反映了加载层面的结构复杂度。
e_shentsize
该字段表示 每个节头表项的大小,单位是字节。
图中该字段的值是:
- 40
也就是说,每个 Section Header Entry 占 40 字节。
配合 e_shnum,就可以计算整个节头表的大小范围。
e_shnum
该字段表示 节头表项的数量。
图中该字段的值是:
- 29
这意味着当前 ELF 一共有 29 个 section。
这些 section 可能包括: - .text
- .data
- .bss
- .rodata
- .dynsym
- .dynstr
- .rel.plt
逆向分析时,e_shnum 可以帮助我们快速判断这个文件的 section 组织规模。
e_shstrndx
该字段表示 节名字字符串表在节头表中的索引。
Program_header_table(程序头表)
如果说 ELF Header 是整个 ELF 的总导航,那么 Program Header Table 就是 ELF 的装载清单。
它不关心“文件里有哪些漂亮的 section 名字”,它只关心一件事:ELF 运行时,哪些内容要被加载到内存,加载到哪里,权限是什么。
我们把程序头表分为三层,程序头项是程序头表中的单个表项,而程序头字段是组成该表项的成员;这些字段共同定义了对应段的类型、位置、大小和权限。
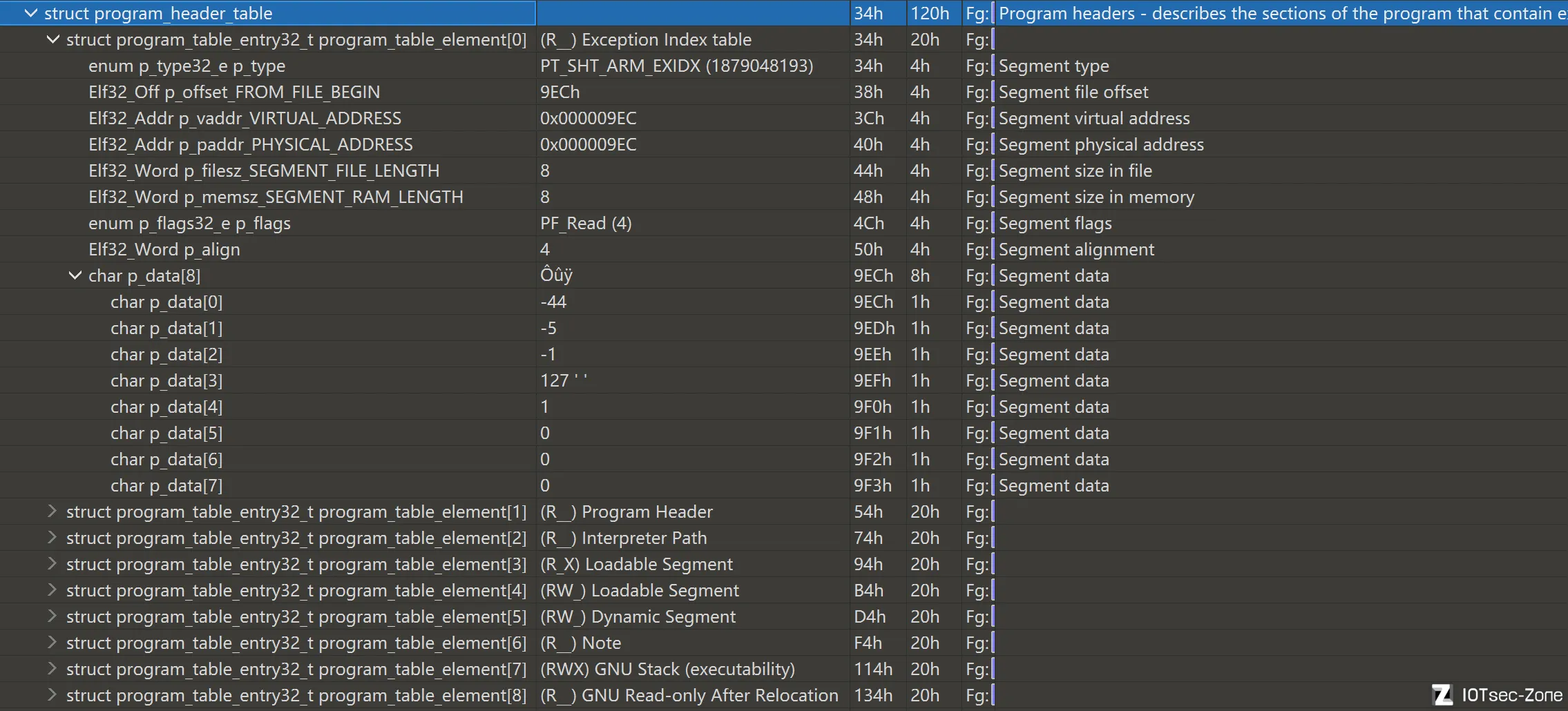
Program Header Entry
程序头表里的每一条记录,叫一个 Program Header Entry,也就是程序头项。每个程序头项都描述一个segment的装载规则,一条程序头项,对应一个 segment。但程序头项不是 segment 本体,程序头项是对这个 segment 的描述记录。
程序头项的通用字段
在不同的程序头项里,最常见的字段基本是一套固定结构。
p_type表示这一项是什么类型的段。这是判断该程序头项“在干什么”的第一入口。常见值包括:
PT_LOAD表示一个真正会被加载进内存的段。
PT_INTERP表示解释器路径,通常就是动态链接器路径。
PT_DYNAMIC表示动态段,这是进入动态链接视图的核心入口。
PT_NOTE表示附加说明信息段。
PT_GNU_STACK表示栈的权限要求。
PT_GNU_RELRO表示一块在重定位完成后会变成只读的区域。
p_offset表示这段内容在文件中的偏移。
p_vaddr表示这段内容装载到内存后的虚拟地址。
p_paddr表示物理地址。在大多数普通 Linux 用户态分析里,这个字段通常不太关键,更多见于某些特定平台或底层场景。
p_filesz表示该段在文件中实际占用的字节数。
p_memsz表示该段装载到内存后占用的字节数。如果 p_memsz > p_filesz,通常说明还有一部分内容需要在内存中补零,比如 .bss。
p_flags 表示该段在内存中的权限。
p_align决定该段在文件和内存中的对齐方式。
Section_Header_table(节头表)
Section Header Table 是一张表。这张表主要给链接器、静态分析器和逆向工具看,而不是给加载器看。它的作用是描述每个 section 的名字、类型、偏移和大小,各个表之间怎么互相索引。它就相当于ELF 的文件内部目录。
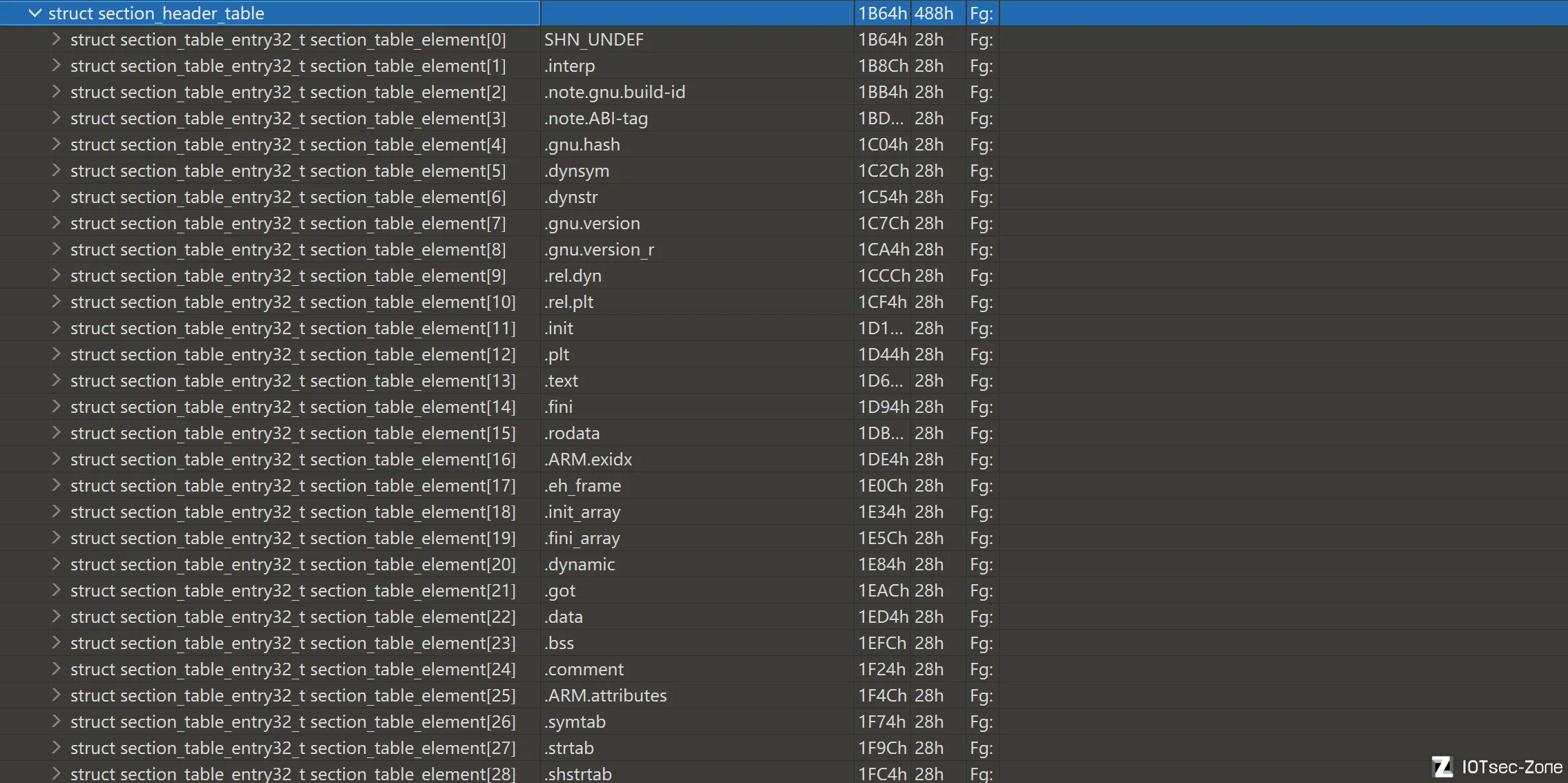
和程序头表一样,它也是三层结构。节头表,节头项和字段。
Section Header Entry
程序头表里的每一条记录,叫一个 Section Header Entry,也就是节头项。每个程序头项都描述一个section的装载规则,一条节头项,对应一个 section。但节头项不是 section 本体,节头项是对这个 section 的描述记录。

节头项的通用字段
不同的 section 类型虽然用途不同,但它们的节头项大体都共享一套字段结构。
sh_name
表示该 section 名字在节名字字符串表中的偏移。
sh_type
表示该 section 的类型。这是判断这个 section “属于哪类数据”的第一入口。
常见值包括:
- SHT_PROGBITS:表示该 section 的内容真实存放在文件里,常见如 .text、.rodata、.data、.plt
- SHT_NOBITS:表示该 section 在文件中通常不真正占据内容,只在内存中分配空间,典型就是 .bss
- SHT_SYMTAB:普通符号表,对静态分析很重要,通常保存更完整的函数名、变量名和本地符号
- SHT_DYNSYM:动态符号表,主要保存动态链接阶段需要解析的符号,常和 .dynstr 配合使用
- SHT_STRTAB:字符串表,主要保存名字字符串,常见有 .strtab、.dynstr、.shstrtab
- SHT_REL:重定位表,不显式保存 addend,常见如 .rel.dyn、.rel.plt
-
- SHT_RELA:重定位表,显式保存 addend,常见于很多 64 位 ELF,如 .rela.dyn、.rela.plt
sh_flags
表示该 section 的属性标志,常见用来说明:是否可写、是否会被装载到内存、是否可执行
sh_addr
表示该 section 装载到内存后的地址,它是内存视角下的值,不是文件偏移。
sh_offset
表示该 section 在文件中的偏移。表示这个 section 在 ELF 文件里从哪开始。
sh_size
表示该 section 的大小。
sh_link
表示该 section 与其他 section 的关联索引,这个字段常用于符号表、字符串表、重定位表之间的关联。
sh_info
表示补充信息,具体含义要看 section 类型,不同 section 的解释方式可能不一样。
sh_addralign
表示该 section 的对齐要求。
sh_entsize
表示该 section 中每个表项的大小,如果该 section 是一个“表”,比如符号表、重定位表,这个字段就很有意义。
常见 section 类型
学习节头表时,最重要的不是把所有 sh_type 都背下来,而是先把最常见、最有分析价值的 section 看懂。
.text
.text 是代码 section,通常存放程序的机器指令。
.rodata
.rodata 是只读数据 section,通常存放字符串常量、格式化字符串、查表数据等。
.data
.data 是已初始化全局变量 section,通常存放程序启动前就有明确初始值的数据。
.bss
.bss 是未初始化全局变量 section。
.symtab
.symtab 是普通符号表,也可以理解成更完整的符号表。
.dynsym
.dynsym 是动态符号表,主要保存动态链接阶段需要的符号。
.strtab
.strtab 是普通字符串表,经常用来存放 .symtab 对应的符号名。
.dynstr
.dynstr 是动态字符串表,通常给:
- .dynsym
- .dynamic
提供名字恢复能力。
.rel. / .rela.**
这类 section 是重定位表。
.got / .got.plt
这两类 section 和全局偏移表、过程链接表密切相关。
Program Header 和 Section Header 的关系
一个 segment 往往包含多个 section。
例如一个代码段可能同时覆盖:
.text.rodata.plt.init
一个数据段可能同时覆盖:.data.bss.got.dynamic
多个 section 会按装载需求和权限,被归并到少数几个 segment 中。
String Table(字符串表)
字符串表本质上就是一块连续的字节区域,里面顺序存放了多个以 \0 结尾的字符串。ELF 里的很多结构并不会直接把名字写进去,而是只保存一个偏移值,真正的名字要去对应的字符串表里取。
所以看到:
sh_namest_nameDT_NEEDED
这类字段它保存的往往不是名字本身,而是指向某个字符串表的索引或偏移。
三类最常见的字符串表
.shstrtab
.shstrtab 是节名字符串表。它专门给节头表服务,用来恢复 section 的名字。
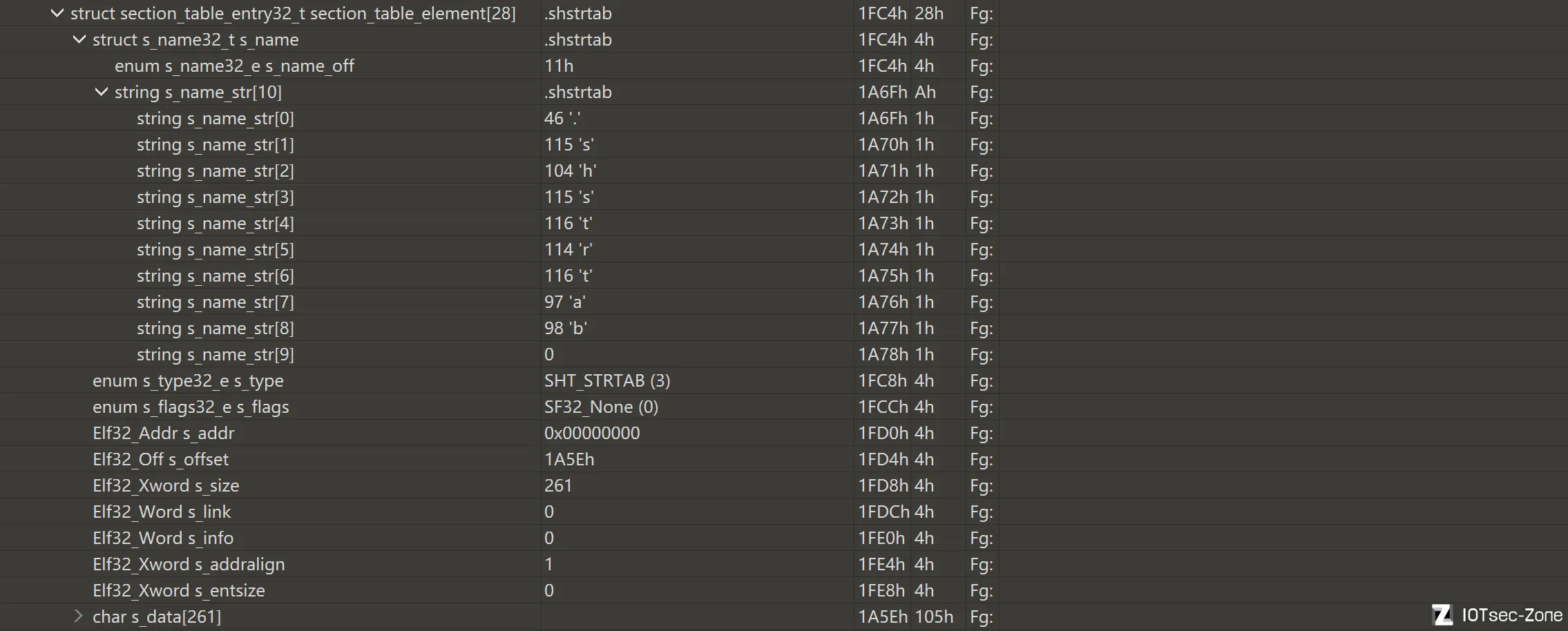
.strtab
.strtab 是普通字符串表。它最常见的作用,是给 .symtab 提供符号名字。
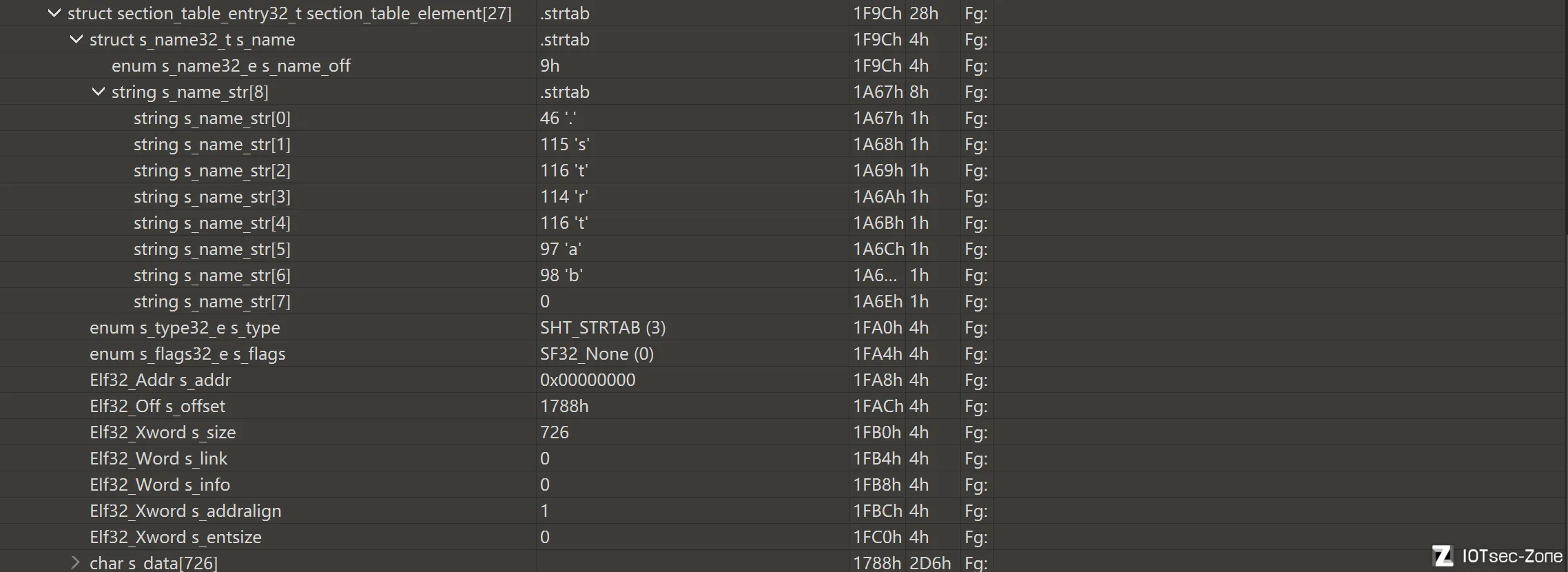
.dynstr
.dynstr 是动态字符串表。它主要给动态链接相关结构提供字符串名字。
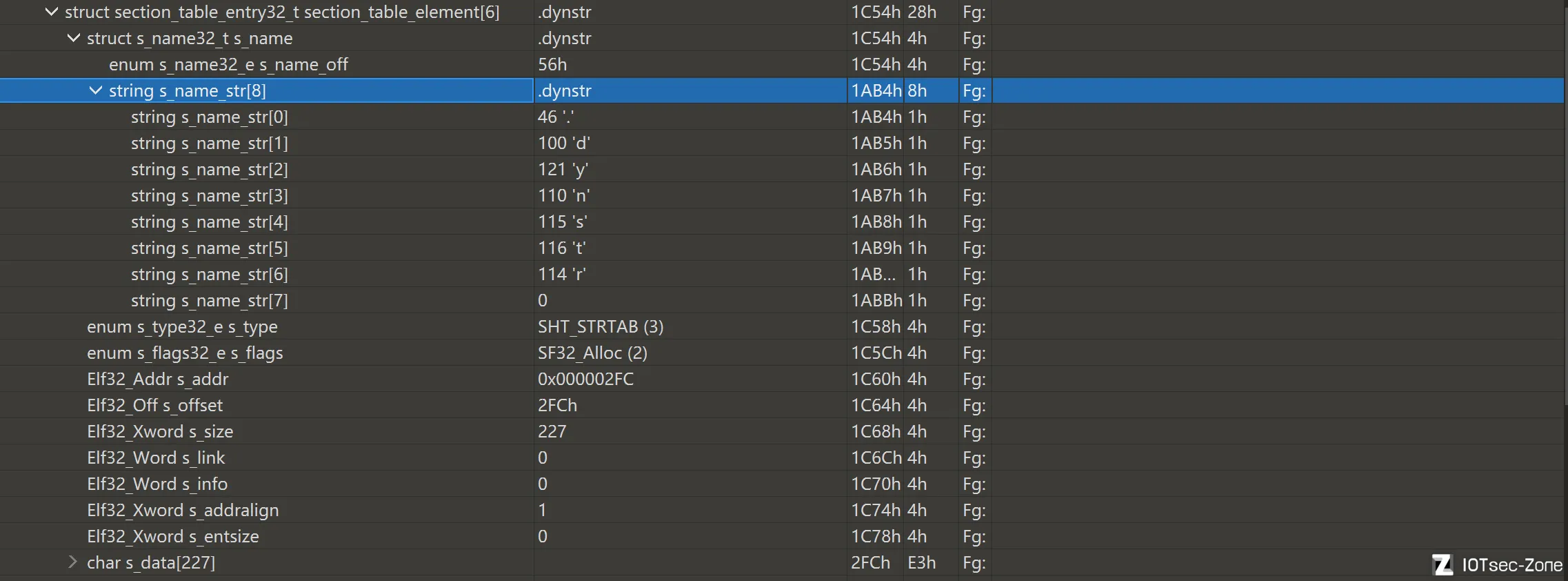
字符串表和字段的对应关系
sh_name->.shstrtabst_name(普通符号)->.strtabst_name(动态符号)->.dynstrDT_NEEDED->.dynstr
所以字符串表不是“单独一张孤立的表”,而是 ELF 里各种名字恢复的基础设施。
ELF 采用的是:结构里只保存偏移,字符串统一放到字符串表里。 这和很多二进制格式里的“索引 + 字符串池”思路是一样的。
看字符串表时,先确认这是哪一类字符串表,再看是谁在引用它,最后根据偏移恢复真正字符串。
例如:
看 section 名字:Section Header Entry->sh_name->.shstrtab
看普通符号名:.symtab->st_name->.strtab
看动态符号或依赖库名:.dynsym/.dynamic->st_name/DT_NEEDED->.dynstr
Symbol Table(符号表)
符号表本质上是一张“名字与地址关系表”,它记录了程序中有意义的目标如: 函数、全局变量、外部引用、局部符号。符号表通常不会把名字完整写在表项里,而是通过 st_name 去对应的字符串表里恢复名字。
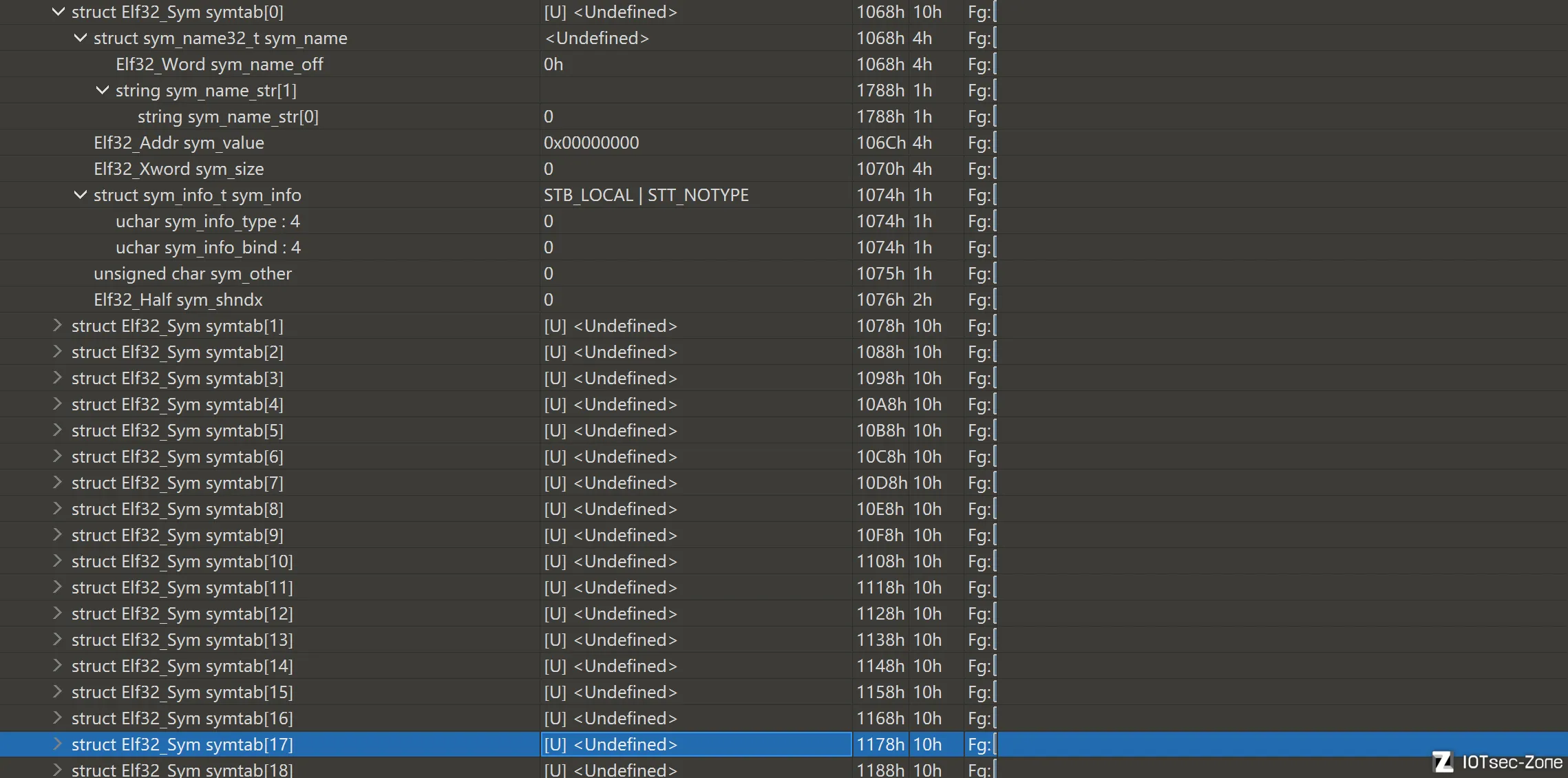
符号表里常见的关键字段
st_name
表示符号名字在字符串表中的偏移,它不直接等于名字本身。
st_value
表示符号值,很多时候可以理解成地址或地址相关值。在函数和全局对象分析里非常重要。
st_size
表示符号大小,对于函数、对象等都可能有意义。
st_info
表示符号类型和绑定方式:是函数还是对象、是本地还是全局
st_shndx
表示该符号所属的 section,这个字段有助于判断符号落在哪个区域里。
Dynamic Segment(动态段)
动态段本质上是一组 DT_* 标签项。它不是单纯的一块“存库名的地方”,而是给动态链接器的指引
动态链接器会根据它知道:依赖了哪些共享库、动态字符串表在哪、动态符号表在哪、重定位表在哪、GOT/PLT 所需入口信息在哪。

Dynamic 里最常见的关键项
DT_NEEDED
表示依赖的共享库,例如程序可能依赖:libc.so.6 -> libm.so.6。这些库名通常不是直接写死在这里,而是通过 .dynstr 恢复。
DT_STRTAB
表示动态字符串表的位置,动态链接过程中,很多名字恢复都离不开它。
DT_SYMTAB
表示动态符号表的位置,动态链接器需要依赖它去解析外部符号。
DT_REL / DT_RELA
表示重定位表位置,它告诉动态链接器:哪些地址需要在运行时被修正。
DT_PLTGOT
表示 GOT 相关入口地址,它和后面的 GOT/PLT 调用链关系非常紧密。
Dynamic Segment 最大的价值是让我们把动态链接的几张关键表串.dynstr;.dynsym、重定位表、GOT / PLT起来:
GOT 与 PLT
GOT 是 Global Offset Table,也就是全局偏移表,也就是一张存地址槽位的表。这些槽位在运行时会被填成真正的目标地址。
PLT 是 Procedure Linkage Table,也就是过程链接表,也就是一组专门用来跳转到外部函数的跳板代码。 GOT:更像“地址表”,PLT:更像“跳板代码”。
程序在编译时,往往还不知道某些共享库函数最终会被加载到哪个地址。这些外部函数的真实地址,往往要等程序运行时才能确定。需要一套机制,让程序先“跳到一个中间层”,再由运行时把真实地址补上。这套机制就是 GOT 和 PLT。
调用外部函数时的大致过程
第一次调用时:
- 程序先跳到 PLT
- PLT 再通过 GOT 找地址
- 此时 GOT 里可能还没有最终地址
- 动态链接器介入,解析符号
- 把真实地址写回 GOT
- 再跳去真正的共享库函数
后续调用:
第一次修好之后,后续再调用同一个函数时,通常就直接通过 GOT 命中真实地址,不需要再完整走一遍解析流程。这就是我们常看到的:第一次调用触发 lazy binding,后续调用直接走已修好的 GOT。
GOT / PLT 相关的关键对象
.got
保存全局偏移表内容,也就是一组地址槽位。
.got.plt
通常和 PLT 配套,保存外部函数调用相关的地址槽位。
.plt
保存过程链接表跳板代码。
.rel.plt / .rela.plt
保存和 PLT 调用链相关的重定位信息。
模仿readelf做一个小的解析器
思路框架
ELF是一整块文件字节,第一步要做的是把整个文件读进内存,再使用Buffer结构保存文件内容指针;文件大小;文件路径。这样我们所有的解析逻辑都会基于这块内存工作,不需要反复的读写操作。第二步就是要做格式判断和格式分流,首先要做校验,先检查文件头,是不是.ELF;再根据[EI_CLASS]判断是32位还是64位。第三步解析ELF Header,通过它拿到全局信息。第四步就是通过ELF Header提供的偏移和数量解析节头表和程序头表。
typedef struct {
unsigned char *data;
size_t size;
const char *path;
} Buffer;
源码
主函数:首先我们规定usage,要求参数必须是一个目标文件的文件路径。紧接着,使用read_file()函数把整个文件读到缓冲区中,确保以后解析都冲buffer缓冲区开始,range_ok()函数确保文件长度够长,它是一个保险函数,我们会多次用到它。memcmp函数确保是ELF结构的,也就是检查文件头是不是.ELF。然后判断格式是32位还是64位,分别根据不同的架构去到不同的函数进行解析。
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "usage: %s <elf-file>\n", argv[0]);
return 1;
}
Buffer buf = read_file(argv[1]);
if (!range_ok(buf.size, 0, EI_NIDENT)) {
free(buf.data);
fail("file too small");
}
if (memcmp(buf.data, ELFMAG, SELFMAG) != 0) {
free(buf.data);
fail("not an ELF file");
}
if (buf.data[EI_DATA] != ELFDATA2LSB) {
free(buf.data);
fail("only little-endian ELF is supported for now");
}
printf("File: %s\n\n", buf.path);
if (buf.data[EI_CLASS] == ELFCLASS32) {
inspect_32(&buf);
} else if (buf.data[EI_CLASS] == ELFCLASS64) {
inspect_64(&buf);
} else {
free(buf.data);
fail("unknown ELF class");
}
free(buf.data);
return 0;
}
read_file()函数,先获取文件的总大小,再分配同样大小的内存,一次性把文件读到内存中,返回一个buffer。
static Buffer read_file(const char *path) {
FILE *fp = fopen(path, "rb");
if (fp == NULL) {
fail_errno("fopen");
}
if (fseek(fp, 0, SEEK_END) != 0) {
fclose(fp);
fail_errno("fseek end");
}
long raw_size = ftell(fp);
if (raw_size < 0) {
fclose(fp);
fail_errno("ftell");
}
if (fseek(fp, 0, SEEK_SET) != 0) {
fclose(fp);
fail_errno("fseek set");
}
unsigned char *data = malloc((size_t)raw_size);
if (data == NULL) {
fclose(fp);
fail("malloc failed");
}
size_t nread = fread(data, 1, (size_t)raw_size, fp);
fclose(fp);
if (nread != (size_t)raw_size) {
free(data);
fail("short read");
}
Buffer buf = {
.data = data,
.size = nread,
.path = path,
};
return buf;
}
inspect_32() 是 32 位 ELF 的主解析流程,这个函数接收一个 Buffer 指针。Buffer 里已经保存好了整份 ELF 文件的内容、大小和路径,所以 inspect_32() 不再负责读文件,只负责解析 32 位 ELF。
static void inspect_32(const Buffer *buf) {
if (!range_ok(buf->size, 0, sizeof(Elf32_Ehdr))) {
fail("file too small for Elf32_Ehdr");
}
const Elf32_Ehdr *eh = (const Elf32_Ehdr *)buf->data;
print_ident(eh->e_ident);
printf(" Type: %s\n", elf_type_name(eh->e_type));
printf(" Machine: %s\n", machine_name(eh->e_machine));
printf(" Entry: 0x%08" PRIx32 "\n", eh->e_entry);
printf(" PHOff: 0x%08" PRIx32 " (%u entries)\n", eh->e_phoff, eh->e_phnum);
printf(" SHOff: 0x%08" PRIx32 " (%u entries)\n", eh->e_shoff, eh->e_shnum);
printf("\n");
这里先确认,从文件偏移 0 开始,至少能取出一个完整的 Elf32_Ehdr。紧接着把文件开头那段字节按 Elf32_Ehdr 的结构布局来读取。 从这里开始,eh->e_entry、eh->e_phoff 这些字段才有意义。紧接着,打印ELF Header。
程序从下面开始转折:首先确保没有越界,然后把程序头表和节头表映射成数组,正式开始按表项遍历ELF结构。
if (!range_ok(buf->size, eh->e_phoff, (uint64_t)eh->e_phnum * eh->e_phentsize)) {
fail("program header table outside file");
}
if (!range_ok(buf->size, eh->e_shoff, (uint64_t)eh->e_shnum * eh->e_shentsize)) {
fail("section header table outside file");
}
const Elf32_Phdr *phdrs = (const Elf32_Phdr *)(buf->data + eh->e_phoff);
const Elf32_Shdr *shdrs = (const Elf32_Shdr *)(buf->data + eh->e_shoff);
打印节头表和程序头表:遍历所有 Elf32_Phdr,打印每个 segment 的:类型、文件偏移、虚拟地址、文件大小、内存大小、权限、对齐值。遍历所有 Elf32_Shdr,打印每个 section 的:名字、类型、地址、偏移、大小、标志位
这里 sh_name 只是一个偏移,必须通过 safe_string() 到 shstrtab 里把名字取出来。
const unsigned char *shstrtab = NULL;
size_t shstrtab_size = 0;
if (eh->e_shstrndx < eh->e_shnum) {
const Elf32_Shdr *shstr = &shdrs[eh->e_shstrndx];
if (range_ok(buf->size, shstr->sh_offset, shstr->sh_size)) {
shstrtab = buf->data + shstr->sh_offset;
shstrtab_size = shstr->sh_size;
}
}
printf("Program Headers:\n");
for (size_t i = 0; i < eh->e_phnum; ++i) {
const Elf32_Phdr *ph = &phdrs[i];
printf(" [%2zu] %-12s off 0x%08" PRIx32 " vaddr 0x%08" PRIx32
" filesz 0x%08" PRIx32 " memsz 0x%08" PRIx32 " flags ",
i, segment_type_name(ph->p_type), ph->p_offset, ph->p_vaddr,
ph->p_filesz, ph->p_memsz);
print_program_flags(ph->p_flags);
printf(" align 0x%" PRIx32 "\n", ph->p_align);
}
printf("\n");
printf("Section Headers:\n");
for (size_t i = 0; i < eh->e_shnum; ++i) {
const Elf32_Shdr *sh = &shdrs[i];
const char *name = shstrtab ? safe_string(shstrtab, shstrtab_size, sh->sh_name) : "<no-shstrtab>";
printf(" [%2zu] %-18s %-12s addr 0x%08" PRIx32 " off 0x%08" PRIx32
" size 0x%08" PRIx32 " flags ",
i, name, section_type_name(sh->sh_type), sh->sh_addr, sh->sh_offset, sh->sh_size);
print_section_flags(sh->sh_flags);
printf("\n");
}
printf("\n");
所有 section 里找到 .dynamic,然后把动态链接相关的信息逐项解析并打印出来。首先遍历所有section,从节头表 shdrs 里一个一个拿 section,找到动态节,然后检查是否越界。紧接着把当前的SHT_DYNAMIC 节对应的文件内容解释成 Elf32_Dyn[],再通过 sh_link 找到它关联的.dynstr。随后逐项遍历每个动态条目,打印它的 d_tag和 d_val;如果条目类型是 DT_NEEDED(依赖共享库)或 DT_SONAME(共享库自身名称),就进一步去字符串表中把偏移还原成真实字符串。遇到
DT_NULL(动态条目结束标记)时停止遍历。
for (size_t i = 0; i < eh->e_shnum; ++i) {
const Elf32_Shdr *sh = &shdrs[i];
if (sh->sh_type != SHT_DYNAMIC) {
continue;
}
if (!range_ok(buf->size, sh->sh_offset, sh->sh_size)) {
continue;
}
printf("Dynamic Section (%zu):\n", i);
const Elf32_Dyn *dyns = (const Elf32_Dyn *)(buf->data + sh->sh_offset);
size_t dyn_count = sh->sh_size / sizeof(Elf32_Dyn);
const unsigned char *dynstr = NULL;
size_t dynstr_size = 0;
if (sh->sh_link < eh->e_shnum) {
const Elf32_Shdr *strsh = &shdrs[sh->sh_link];
if (range_ok(buf->size, strsh->sh_offset, strsh->sh_size)) {
dynstr = buf->data + strsh->sh_offset;
dynstr_size = strsh->sh_size;
}
}
for (size_t j = 0; j < dyn_count; ++j) {
printf(" [%2zu] %-14s 0x%08" PRIx32, j, dyn_tag_name(dyns[j].d_tag), dyns[j].d_un.d_val);
if ((dyns[j].d_tag == DT_NEEDED || dyns[j].d_tag == DT_SONAME) && dynstr != NULL) {
printf(" %s", safe_string(dynstr, dynstr_size, dyns[j].d_un.d_val));
}
printf("\n");
if (dyns[j].d_tag == DT_NULL) {
break;
}
}
printf("\n");
}
接下来就是找符号表,筛选出 SHT_SYMTAB(普通符号表)和 SHT_DYNSYM(动态符号表)这两类 section,随后通过当前符号表 section 的 sh_link 找到它关联的字符串表(string table),这样后面就能把每个符号项中的 st_name(符号名偏移)还原成真正的函数名或变量名。
for (size_t i = 0; i < eh->e_shnum; ++i) {
const Elf32_Shdr *sh = &shdrs[i];
if (sh->sh_type != SHT_SYMTAB && sh->sh_type != SHT_DYNSYM) {
continue;
}
if (!range_ok(buf->size, sh->sh_offset, sh->sh_size)) {
continue;
}
const char *sec_name = shstrtab ? safe_string(shstrtab, shstrtab_size, sh->sh_name) : "<symtab>";
const unsigned char *strtab = NULL;
size_t strtab_size = 0;
if (sh->sh_link < eh->e_shnum) {
const Elf32_Shdr *strsh = &shdrs[sh->sh_link];
if (range_ok(buf->size, strsh->sh_offset, strsh->sh_size)) {
strtab = buf->data + strsh->sh_offset;
strtab_size = strsh->sh_size;
}
}
printf("Symbols in %s:\n", sec_name);
const Elf32_Sym *syms = (const Elf32_Sym *)(buf->data + sh->sh_offset);
size_t sym_count = sh->sh_size / sizeof(Elf32_Sym);
for (size_t j = 0; j < sym_count; ++j) {
const char *name = strtab ? safe_string(strtab, strtab_size, syms[j].st_name) : "<no-strtab>";
printf(" [%3zu] %-24s value 0x%08" PRIx32 " size %-5" PRIu32 " bind %-6s type %-8s shndx %u\n",
j, name, syms[j].st_value, syms[j].st_size,
symbol_bind_name(ELF32_ST_BIND(syms[j].st_info)),
symbol_type_name(ELF32_ST_TYPE(syms[j].st_info)),
syms[j].st_shndx);
}
printf("\n");
}
重定位表,原理如上,筛选出 SHT_REL(不带显式附加数的重定位表)和 SHT_RELA(带显式附加数 addend 的重定位表)这两类 section,程序通过当前重定位节的 sh_link 找到它关联的符号表(symbol table),再继续通过该符号表的 sh_link 找到对应的字符串表(string table),这样后面就能把重定位项里关联的符号索引还原成真实符号名。接着,如果当前节是 SHT_REL,就把内容解释成 Elf32_Rel[];如果是 SHT_RELA,就解释成 Elf32_Rela[]。遍历每个重定位项时,程序会从 r_info 中拆出 ELF32_R_TYPE(重定位类型)和 ELF32_R_SYM(关联符号索引),再结合 r_offse(需要修补的位置)以及可能存在的 r_addend(附加数),把每条重定位记录打印出来。
for (size_t i = 0; i < eh->e_shnum; ++i) {
const Elf32_Shdr *sh = &shdrs[i];
if (sh->sh_type != SHT_REL && sh->sh_type != SHT_RELA) {
continue;
}
if (!range_ok(buf->size, sh->sh_offset, sh->sh_size)) {
continue;
}
const char *sec_name = shstrtab ? safe_string(shstrtab, shstrtab_size, sh->sh_name) : "<rel>";
printf("Relocations in %s:\n", sec_name);
const unsigned char *sym_strtab = NULL;
size_t sym_strtab_size = 0;
const Elf32_Sym *symtab = NULL;
size_t sym_count = 0;
if (sh->sh_link < eh->e_shnum) {
const Elf32_Shdr *symsh = &shdrs[sh->sh_link];
if (range_ok(buf->size, symsh->sh_offset, symsh->sh_size)) {
symtab = (const Elf32_Sym *)(buf->data + symsh->sh_offset);
sym_count = symsh->sh_size / sizeof(Elf32_Sym);
if (symsh->sh_link < eh->e_shnum) {
const Elf32_Shdr *strsh = &shdrs[symsh->sh_link];
if (range_ok(buf->size, strsh->sh_offset, strsh->sh_size)) {
sym_strtab = buf->data + strsh->sh_offset;
sym_strtab_size = strsh->sh_size;
}
}
}
}
if (sh->sh_type == SHT_REL) {
const Elf32_Rel *rels = (const Elf32_Rel *)(buf->data + sh->sh_offset);
size_t rel_count = sh->sh_size / sizeof(Elf32_Rel);
for (size_t j = 0; j < rel_count; ++j) {
uint32_t sym_idx = ELF32_R_SYM(rels[j].r_info);
const char *name = "<no-symbol>";
if (symtab != NULL && sym_idx < sym_count && sym_strtab != NULL) {
name = safe_string(sym_strtab, sym_strtab_size, symtab[sym_idx].st_name);
}
printf(" [%3zu] off 0x%08" PRIx32 " type %-4u sym %-4u %s\n",
j, rels[j].r_offset, ELF32_R_TYPE(rels[j].r_info), sym_idx, name);
}
} else {
const Elf32_Rela *rels = (const Elf32_Rela *)(buf->data + sh->sh_offset);
size_t rel_count = sh->sh_size / sizeof(Elf32_Rela);
for (size_t j = 0; j < rel_count; ++j) {
uint32_t sym_idx = ELF32_R_SYM(rels[j].r_info);
const char *name = "<no-symbol>";
if (symtab != NULL && sym_idx < sym_count && sym_strtab != NULL) {
name = safe_string(sym_strtab, sym_strtab_size, symtab[sym_idx].st_name);
}
printf(" [%3zu] off 0x%08" PRIx32 " type %-4u sym %-4u addend 0x%08" PRIx32 " %s\n",
j, rels[j].r_offset, ELF32_R_TYPE(rels[j].r_info), sym_idx, (uint32_t)rels[j].r_addend, name);
}
}
printf("\n");
}
最后,这部分代码先遍历程序头表(program header table),筛选出 PT_DYNAMIC(动态段)类型的段,并打印它在内存中的 p_vaddr(虚拟地址virtual address)与在文件中的 p_offset(文件偏移 file offset)之间的对应关系,用来说明这块动态链接数据在“装载视图”和“文件视图”中分别落在哪里。随后程序调用 vaddr_to_offset32(),把 ELF Header 中的 e_entry(程序入口虚拟地址 entry point)反推成文件里的实际偏移位置;如果换算成功,就打印这个入口点对应的文件偏移。整体作用就是建立 ELF 的内存地址和文件偏移之间的映射关系,帮助我们把运行时视角(virtual address)重新对应回静态文件视角(file offset)。
for (size_t i = 0; i < eh->e_phnum; ++i) {
const Elf32_Phdr *ph = &phdrs[i];
if (ph->p_type != PT_DYNAMIC) {
continue;
}
printf("PT_DYNAMIC maps vaddr 0x%08" PRIx32 " to file offset 0x%08" PRIx32 "\n",
ph->p_vaddr, ph->p_offset);
}
uint64_t entry_offset = vaddr_to_offset32(phdrs, eh->e_phnum, eh->e_entry);
if (entry_offset != UINT64_MAX) {
printf("Entry point file offset: 0x%08" PRIx64 "\n", entry_offset);
}
}
inspect_64()函数的大致原理也就是这些,make之后最后看一下我们的程序效果:
./elf_inspect /home/iotsec-zone/Desktop/ELF/first-arm
File: /home/iotsec-zone/Desktop/ELF/first-arm
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: Little Endian
Type: DYN
Machine: ARM
Entry: 0x000005c1
PHOff: 0x00000034 (9 entries)
SHOff: 0x00001b64 (29 entries)
Program Headers:
[ 0] OTHER off 0x000009ec vaddr 0x000009ec filesz 0x00000008 memsz 0x00000008 flags R-- align 0x4
[ 1] PHDR off 0x00000034 vaddr 0x00000034 filesz 0x00000120 memsz 0x00000120 flags R-- align 0x4
[ 2] INTERP off 0x00000154 vaddr 0x00000154 filesz 0x00000019 memsz 0x00000019 flags R-- align 0x1
[ 3] LOAD off 0x00000000 vaddr 0x00000000 filesz 0x000009f8 memsz 0x000009f8 flags R-E align 0x10000
[ 4] LOAD off 0x00000ea8 vaddr 0x00010ea8 filesz 0x00000160 memsz 0x00000164 flags RW- align 0x10000
[ 5] DYNAMIC off 0x00000eb0 vaddr 0x00010eb0 filesz 0x000000f8 memsz 0x000000f8 flags RW- align 0x4
[ 6] NOTE off 0x00000170 vaddr 0x00000170 filesz 0x00000044 memsz 0x00000044 flags R-- align 0x4
[ 7] GNU_STACK off 0x00000000 vaddr 0x00000000 filesz 0x00000000 memsz 0x00000000 flags RWE align 0x10
[ 8] GNU_RELRO off 0x00000ea8 vaddr 0x00010ea8 filesz 0x00000158 memsz 0x00000158 flags R-- align 0x1
Section Headers:
[ 0] NULL addr 0x00000000 off 0x00000000 size 0x00000000 flags ---
[ 1] .interp PROGBITS addr 0x00000154 off 0x00000154 size 0x00000019 flags -A-
[ 2] .note.gnu.build-id NOTE addr 0x00000170 off 0x00000170 size 0x00000024 flags -A-
[ 3] .note.ABI-tag NOTE addr 0x00000194 off 0x00000194 size 0x00000020 flags -A-
[ 4] .gnu.hash OTHER addr 0x000001b4 off 0x000001b4 size 0x00000018 flags -A-
[ 5] .dynsym DYNSYM addr 0x000001cc off 0x000001cc size 0x00000130 flags -A-
[ 6] .dynstr STRTAB addr 0x000002fc off 0x000002fc size 0x000000e3 flags -A-
[ 7] .gnu.version OTHER addr 0x000003e0 off 0x000003e0 size 0x00000026 flags -A-
[ 8] .gnu.version_r OTHER addr 0x00000408 off 0x00000408 size 0x00000040 flags -A-
[ 9] .rel.dyn REL addr 0x00000448 off 0x00000448 size 0x00000040 flags -A-
[10] .rel.plt REL addr 0x00000488 off 0x00000488 size 0x00000070 flags -A-
[11] .init PROGBITS addr 0x000004f8 off 0x000004f8 size 0x0000000c flags -AX
[12] .plt PROGBITS addr 0x00000504 off 0x00000504 size 0x000000bc flags -AX
[13] .text PROGBITS addr 0x000005c0 off 0x000005c0 size 0x00000258 flags -AX
[14] .fini PROGBITS addr 0x00000818 off 0x00000818 size 0x00000008 flags -AX
[15] .rodata PROGBITS addr 0x00000820 off 0x00000820 size 0x000001cc flags -A-
[16] .ARM.exidx OTHER addr 0x000009ec off 0x000009ec size 0x00000008 flags -A-
[17] .eh_frame PROGBITS addr 0x000009f4 off 0x000009f4 size 0x00000004 flags -A-
[18] .init_array INIT_ARRAY addr 0x00010ea8 off 0x00000ea8 size 0x00000004 flags WA-
[19] .fini_array FINI_ARRAY addr 0x00010eac off 0x00000eac size 0x00000004 flags WA-
[20] .dynamic DYNAMIC addr 0x00010eb0 off 0x00000eb0 size 0x000000f8 flags WA-
[21] .got PROGBITS addr 0x00010fa8 off 0x00000fa8 size 0x00000058 flags WA-
[22] .data PROGBITS addr 0x00011000 off 0x00001000 size 0x00000008 flags WA-
[23] .bss NOBITS addr 0x00011008 off 0x00001008 size 0x00000004 flags WA-
[24] .comment PROGBITS addr 0x00000000 off 0x00001008 size 0x0000002d flags ---
[25] .ARM.attributes OTHER addr 0x00000000 off 0x00001035 size 0x00000033 flags ---
[26] .symtab SYMTAB addr 0x00000000 off 0x00001068 size 0x00000720 flags ---
[27] .strtab STRTAB addr 0x00000000 off 0x00001788 size 0x000002d6 flags ---
[28] .shstrtab STRTAB addr 0x00000000 off 0x00001a5e size 0x00000105 flags ---
Dynamic Section (20):
[ 0] NEEDED 0x00000075 libc.so.6
[ 1] INIT 0x000004f8
[ 2] FINI 0x00000818
[ 3] INIT_ARRAY 0x00010ea8
[ 4] INIT_ARRAYSZ 0x00000004
[ 5] FINI_ARRAY 0x00010eac
[ 6] FINI_ARRAYSZ 0x00000004
[ 7] GNU_HASH 0x000001b4
[ 8] STRTAB 0x000002fc
[ 9] SYMTAB 0x000001cc
[10] STRSZ 0x000000e3
[11] SYMENT 0x00000010
[12] DEBUG 0x00000000
[13] PLTGOT 0x00010fa8
[14] PLTRELSZ 0x00000070
[15] PLTREL 0x00000011
[16] JMPREL 0x00000488
[17] REL 0x00000448
[18] RELSZ 0x00000040
[19] RELENT 0x00000008
[20] OTHER 0x00000008
[21] OTHER 0x08000001
[22] OTHER 0x00000408
[23] OTHER 0x00000001
[24] OTHER 0x000003e0
[25] OTHER 0x00000004
[26] NULL 0x00000000
Symbols in .dynsym:
[ 0] value 0x00000000 size 0 bind LOCAL type NOTYPE shndx 0
[ 1] value 0x000004f8 size 0 bind LOCAL type SECTION shndx 11
[ 2] value 0x00011000 size 0 bind LOCAL type SECTION shndx 22
[ 3] __libc_start_main value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 4] __cxa_finalize value 0x00000000 size 0 bind WEAK type FUNC shndx 0
[ 5] _ITM_deregisterTMCloneTable value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[ 6] printf value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 7] fopen value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 8] fgets value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 9] perror value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 10] strcpy value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 11] puts value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 12] __gmon_start__ value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[ 13] fprintf value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 14] __isoc99_sscanf value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 15] fclose value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 16] __isoc99_scanf value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 17] _ITM_registerTMCloneTable value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[ 18] abort value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
Symbols in .symtab:
[ 0] value 0x00000000 size 0 bind LOCAL type NOTYPE shndx 0
[ 1] value 0x00000154 size 0 bind LOCAL type SECTION shndx 1
[ 2] value 0x00000170 size 0 bind LOCAL type SECTION shndx 2
[ 3] value 0x00000194 size 0 bind LOCAL type SECTION shndx 3
[ 4] value 0x000001b4 size 0 bind LOCAL type SECTION shndx 4
[ 5] value 0x000001cc size 0 bind LOCAL type SECTION shndx 5
[ 6] value 0x000002fc size 0 bind LOCAL type SECTION shndx 6
[ 7] value 0x000003e0 size 0 bind LOCAL type SECTION shndx 7
[ 8] value 0x00000408 size 0 bind LOCAL type SECTION shndx 8
[ 9] value 0x00000448 size 0 bind LOCAL type SECTION shndx 9
[ 10] value 0x00000488 size 0 bind LOCAL type SECTION shndx 10
[ 11] value 0x000004f8 size 0 bind LOCAL type SECTION shndx 11
[ 12] value 0x00000504 size 0 bind LOCAL type SECTION shndx 12
[ 13] value 0x000005c0 size 0 bind LOCAL type SECTION shndx 13
[ 14] value 0x00000818 size 0 bind LOCAL type SECTION shndx 14
[ 15] value 0x00000820 size 0 bind LOCAL type SECTION shndx 15
[ 16] value 0x000009ec size 0 bind LOCAL type SECTION shndx 16
[ 17] value 0x000009f4 size 0 bind LOCAL type SECTION shndx 17
[ 18] value 0x00010ea8 size 0 bind LOCAL type SECTION shndx 18
[ 19] value 0x00010eac size 0 bind LOCAL type SECTION shndx 19
[ 20] value 0x00010eb0 size 0 bind LOCAL type SECTION shndx 20
[ 21] value 0x00010fa8 size 0 bind LOCAL type SECTION shndx 21
[ 22] value 0x00011000 size 0 bind LOCAL type SECTION shndx 22
[ 23] value 0x00011008 size 0 bind LOCAL type SECTION shndx 23
[ 24] value 0x00000000 size 0 bind LOCAL type SECTION shndx 24
[ 25] value 0x00000000 size 0 bind LOCAL type SECTION shndx 25
[ 26] Scrt1.o value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 27] $d value 0x00000194 size 0 bind LOCAL type NOTYPE shndx 3
[ 28] __abi_tag value 0x00000194 size 32 bind LOCAL type OBJECT shndx 3
[ 29] $t value 0x000005c0 size 0 bind LOCAL type NOTYPE shndx 13
[ 30] $d value 0x000005ec size 0 bind LOCAL type NOTYPE shndx 13
[ 31] $d value 0x000009ec size 0 bind LOCAL type NOTYPE shndx 16
[ 32] $d value 0x00000820 size 0 bind LOCAL type NOTYPE shndx 15
[ 33] $d value 0x00011000 size 0 bind LOCAL type NOTYPE shndx 22
[ 34] crti.o value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 35] $a value 0x000005f4 size 0 bind LOCAL type NOTYPE shndx 13
[ 36] call_weak_fn value 0x000005f4 size 0 bind LOCAL type FUNC shndx 13
[ 37] $d value 0x00000610 size 0 bind LOCAL type NOTYPE shndx 13
[ 38] $a value 0x000004f8 size 0 bind LOCAL type NOTYPE shndx 11
[ 39] $a value 0x00000818 size 0 bind LOCAL type NOTYPE shndx 14
[ 40] crtn.o value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 41] $a value 0x00000500 size 0 bind LOCAL type NOTYPE shndx 11
[ 42] $a value 0x0000081c size 0 bind LOCAL type NOTYPE shndx 14
[ 43] crtstuff.c value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 44] $d value 0x00000824 size 0 bind LOCAL type NOTYPE shndx 15
[ 45] all_implied_fbits value 0x00000824 size 0 bind LOCAL type OBJECT shndx 15
[ 46] $t value 0x00000618 size 0 bind LOCAL type NOTYPE shndx 13
[ 47] deregister_tm_clones value 0x00000619 size 0 bind LOCAL type FUNC shndx 13
[ 48] $d value 0x00000634 size 0 bind LOCAL type NOTYPE shndx 13
[ 49] $t value 0x00000644 size 0 bind LOCAL type NOTYPE shndx 13
[ 50] register_tm_clones value 0x00000645 size 0 bind LOCAL type FUNC shndx 13
[ 51] $d value 0x00000668 size 0 bind LOCAL type NOTYPE shndx 13
[ 52] $d value 0x00011004 size 0 bind LOCAL type NOTYPE shndx 22
[ 53] $t value 0x00000678 size 0 bind LOCAL type NOTYPE shndx 13
[ 54] __do_global_dtors_aux value 0x00000679 size 0 bind LOCAL type FUNC shndx 13
[ 55] $d value 0x000006a4 size 0 bind LOCAL type NOTYPE shndx 13
[ 56] completed.0 value 0x00011008 size 1 bind LOCAL type OBJECT shndx 23
[ 57] $d value 0x00010eac size 0 bind LOCAL type NOTYPE shndx 19
[ 58] __do_global_dtors_aux_fini_array_entry value 0x00010eac size 0 bind LOCAL type OBJECT shndx 19
[ 59] $t value 0x000006b8 size 0 bind LOCAL type NOTYPE shndx 13
[ 60] frame_dummy value 0x000006b9 size 0 bind LOCAL type FUNC shndx 13
[ 61] $d value 0x00010ea8 size 0 bind LOCAL type NOTYPE shndx 18
[ 62] __frame_dummy_init_array_entry value 0x00010ea8 size 0 bind LOCAL type OBJECT shndx 18
[ 63] $d value 0x00011008 size 0 bind LOCAL type NOTYPE shndx 23
[ 64] first-arm.c value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 65] $d value 0x000008b4 size 0 bind LOCAL type NOTYPE shndx 15
[ 66] $t value 0x000006bc size 0 bind LOCAL type NOTYPE shndx 13
[ 67] $d value 0x00000758 size 0 bind LOCAL type NOTYPE shndx 13
[ 68] $t value 0x00000774 size 0 bind LOCAL type NOTYPE shndx 13
[ 69] $d value 0x000007f8 size 0 bind LOCAL type NOTYPE shndx 13
[ 70] crtstuff.c value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 71] $d value 0x0000095c size 0 bind LOCAL type NOTYPE shndx 15
[ 72] all_implied_fbits value 0x0000095c size 0 bind LOCAL type OBJECT shndx 15
[ 73] $d value 0x000009f4 size 0 bind LOCAL type NOTYPE shndx 17
[ 74] __FRAME_END__ value 0x000009f4 size 0 bind LOCAL type OBJECT shndx 17
[ 75] value 0x00000000 size 0 bind LOCAL type FILE shndx 65521
[ 76] _DYNAMIC value 0x00010eb0 size 0 bind LOCAL type OBJECT shndx 65521
[ 77] _GLOBAL_OFFSET_TABLE_ value 0x00010fa8 size 0 bind LOCAL type OBJECT shndx 65521
[ 78] $a value 0x00000504 size 0 bind LOCAL type NOTYPE shndx 12
[ 79] $d value 0x00000514 size 0 bind LOCAL type NOTYPE shndx 12
[ 80] $a value 0x00000518 size 0 bind LOCAL type NOTYPE shndx 12
[ 81] __libc_start_main@GLIBC_2.34 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 82] __cxa_finalize@GLIBC_2.4 value 0x00000000 size 0 bind WEAK type FUNC shndx 0
[ 83] _ITM_deregisterTMCloneTable value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[ 84] data_start value 0x00011000 size 0 bind WEAK type NOTYPE shndx 22
[ 85] printf@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 86] __bss_start__ value 0x00011008 size 0 bind GLOBAL type NOTYPE shndx 23
[ 87] fopen@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 88] fgets@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 89] _bss_end__ value 0x0001100c size 0 bind GLOBAL type NOTYPE shndx 23
[ 90] _edata value 0x00011008 size 0 bind GLOBAL type NOTYPE shndx 22
[ 91] _fini value 0x00000818 size 0 bind GLOBAL type FUNC shndx 14
[ 92] __bss_end__ value 0x0001100c size 0 bind GLOBAL type NOTYPE shndx 23
[ 93] perror@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 94] strcpy@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 95] __data_start value 0x00011000 size 0 bind GLOBAL type NOTYPE shndx 22
[ 96] puts@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[ 97] __gmon_start__ value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[ 98] __dso_handle value 0x00011004 size 0 bind GLOBAL type OBJECT shndx 22
[ 99] _IO_stdin_used value 0x00000820 size 4 bind GLOBAL type OBJECT shndx 15
[100] fprintf@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[101] __isoc99_sscanf@GLIBC_2.7 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[102] _end value 0x0001100c size 0 bind GLOBAL type NOTYPE shndx 23
[103] _start value 0x000005c1 size 0 bind GLOBAL type FUNC shndx 13
[104] read_and_copy value 0x000006bd size 184 bind GLOBAL type FUNC shndx 13
[105] __end__ value 0x0001100c size 0 bind GLOBAL type NOTYPE shndx 23
[106] __bss_start value 0x00011008 size 0 bind GLOBAL type NOTYPE shndx 23
[107] fclose@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[108] main value 0x00000775 size 164 bind GLOBAL type FUNC shndx 13
[109] __isoc99_scanf@GLIBC_2.7 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[110] __TMC_END__ value 0x00011008 size 0 bind GLOBAL type OBJECT shndx 22
[111] _ITM_registerTMCloneTable value 0x00000000 size 0 bind WEAK type NOTYPE shndx 0
[112] abort@GLIBC_2.4 value 0x00000000 size 0 bind GLOBAL type FUNC shndx 0
[113] _init value 0x000004f8 size 0 bind GLOBAL type FUNC shndx 11
Relocations in .rel.dyn:
[ 0] off 0x00010ea8 type 23 sym 0
[ 1] off 0x00010eac type 23 sym 0
[ 2] off 0x00010ff8 type 23 sym 0
[ 3] off 0x00011004 type 23 sym 0
[ 4] off 0x00010fec type 21 sym 4 __cxa_finalize
[ 5] off 0x00010ff0 type 21 sym 5 _ITM_deregisterTMCloneTable
[ 6] off 0x00010ff4 type 21 sym 12 __gmon_start__
[ 7] off 0x00010ffc type 21 sym 17 _ITM_registerTMCloneTable
Relocations in .rel.plt:
[ 0] off 0x00010fb4 type 22 sym 3 __libc_start_main
[ 1] off 0x00010fb8 type 22 sym 4 __cxa_finalize
[ 2] off 0x00010fbc type 22 sym 6 printf
[ 3] off 0x00010fc0 type 22 sym 7 fopen
[ 4] off 0x00010fc4 type 22 sym 8 fgets
[ 5] off 0x00010fc8 type 22 sym 9 perror
[ 6] off 0x00010fcc type 22 sym 10 strcpy
[ 7] off 0x00010fd0 type 22 sym 11 puts
[ 8] off 0x00010fd4 type 22 sym 12 __gmon_start__
[ 9] off 0x00010fd8 type 22 sym 13 fprintf
[ 10] off 0x00010fdc type 22 sym 14 __isoc99_sscanf
[ 11] off 0x00010fe0 type 22 sym 15 fclose
[ 12] off 0x00010fe4 type 22 sym 16 __isoc99_scanf
[ 13] off 0x00010fe8 type 22 sym 18 abort
PT_DYNAMIC maps vaddr 0x00010eb0 to file offset 0x00000eb0
Entry point file offset: 0x000005c1
Mini Loader
mini_loader是在elf_inspect基础上向前走一步的最小 loader 示例。它不执行 ELF,只做一件事:把所有 PT_LOAD 段装进一块模拟内存(image)里,并算出入口点在 image 中的位置。
库函数以及结构体:
#include <elf.h>
#include <errno.h>
#include <inttypes.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
unsigned char *data;
size_t size;
const char *path;
} Buffer;
typedef struct {
uint8_t *image;
uint64_t image_size;
uint64_t min_vaddr;
uint64_t max_vaddr;
uint64_t entry_vaddr;
uint64_t entry_offset_in_image;
uint16_t machine;
uint16_t type;
int elf_class;
} LoadedImage;
思路框架
定位 Program Header Table,遍历所有 PT_LOAD,计算所有可加载段覆盖的最小虚拟地址 min_vaddr,计算所有可加载段覆盖的最大虚拟地址 max_vaddr,用 max_vaddr - min_vaddr 分配整块image,把每个 PT_LOAD 的文件内容复制到 image 中,对 p_memsz > p_filesz 的部分补零,计算入口点在 image 中的偏移。为了更好的演示,我们将关键信息打印出来。
源码
主函数和解析器一样,通过read_file()将文件读进内存,用安全函数rang_ok保证符合标准,遍历分流。
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "usage: %s <elf-file>\n", argv[0]);
return 1;
}
Buffer buf = read_file(argv[1]);mini_loader /home/iotsec-zone/Desktop/ELF/first-arm
mini_loader: command not found
if (!range_ok(buf.size, 0, EI_NIDENT)) {
free(buf.data);
fail("file too small");
}
if (memcmp(buf.data, ELFMAG, SELFMAG) != 0) {
free(buf.data);
fail("not an ELF file");
}
if (buf.data[EI_DATA] != ELFDATA2LSB) {
free(buf.data);
fail("only little-endian ELF is supported for now");
}
printf("File: %s\n\n", buf.path);
LoadedImage image;
if (buf.data[EI_CLASS] == ELFCLASS32) {
image = load32(&buf);
} else if (buf.data[EI_CLASS] == ELFCLASS64) {
image = load64(&buf);
} else {
free(buf.data);
fail("unknown ELF class");
}
printf("\n");
printf("Summary:\n");
printf(" class ELF%d\n", image.elf_class == ELFCLASS32 ? 32 : 64);
printf(" machine %s\n", machine_name(image.machine));
printf(" min vaddr 0x%08" PRIx64 "\n", image.min_vaddr);
printf(" max vaddr 0x%08" PRIx64 "\n", image.max_vaddr);
printf(" entry vaddr 0x%08" PRIx64 "\n", image.entry_vaddr);
printf(" entry image 0x%08" PRIx64 "\n", image.entry_offset_in_image);
free(image.image);
free(buf.data);
return 0;
}
主要代码:主要是为了复现ELF文件从硬盘到内存的装载过程,首先遍历程序头,筛选出PT_LOAD段。,一边校验这些段在文件中的内容是否完整,一边统计所有加载段覆盖的最小虚拟地址和最大虚拟地址,用来确定整个内存映像(image,内存镜像)的范围;接着按这个范围申请一块清零内存,把每个加载段从文件偏移复制到映像中对应的位置,并对 p_memsz 大于 p_filesz 的部分补零,模拟未初始化数据区(如 .bss)在内存中的状态;最后计算入口点(entry,入口地址)在这块映像中的偏移,连同映像范围、机器类型、ELF 类别等信息一起封装进 LoadedImage 结构返回。
static LoadedImage load32(const Buffer *buf) {
if (!range_ok(buf->size, 0, sizeof(Elf32_Ehdr))) {
fail("file too small for Elf32_Ehdr");
}
const Elf32_Ehdr *eh = (const Elf32_Ehdr *)buf->data;
if (!range_ok(buf->size, eh->e_phoff, (uint64_t)eh->e_phnum * eh->e_phentsize)) {
fail("program header table outside file");
}
const Elf32_Phdr *phdrs = (const Elf32_Phdr *)(buf->data + eh->e_phoff);
uint64_t min_vaddr = UINT64_MAX;
uint64_t max_vaddr = 0;
bool found_load = false;
for (size_t i = 0; i < eh->e_phnum; ++i) {
const Elf32_Phdr *ph = &phdrs[i];
if (ph->p_type != PT_LOAD) {
continue;
}
if (!range_ok(buf->size, ph->p_offset, ph->p_filesz)) {
fail("PT_LOAD contents outside file");
}
if (!found_load || ph->p_vaddr < min_vaddr) {
min_vaddr = ph->p_vaddr;
}
if ((uint64_t)ph->p_vaddr + ph->p_memsz > max_vaddr) {
max_vaddr = (uint64_t)ph->p_vaddr + ph->p_memsz;
}
found_load = true;
}
if (!found_load || max_vaddr < min_vaddr) {
fail("no PT_LOAD segments found");
}
uint64_t image_size = max_vaddr - min_vaddr;
uint8_t *image = calloc(1, (size_t)image_size);
if (image == NULL) {
fail("calloc failed");
}
printf("ELF32 loader plan:\n");
printf(" machine %s\n", machine_name(eh->e_machine));
printf(" image range [0x%08" PRIx64 ", 0x%08" PRIx64 ")\n", min_vaddr, max_vaddr);
printf(" image size 0x%08" PRIx64 "\n", image_size);
printf(" entry vaddr 0x%08" PRIx32 "\n", eh->e_entry);
printf("\n");
for (size_t i = 0; i < eh->e_phnum; ++i) {
const Elf32_Phdr *ph = &phdrs[i];
if (ph->p_type != PT_LOAD) {
continue;
}
uint64_t image_off = ph->p_vaddr - min_vaddr;
memcpy(image + image_off, buf->data + ph->p_offset, ph->p_filesz);
if (ph->p_memsz > ph->p_filesz) {
memset(image + image_off + ph->p_filesz, 0, ph->p_memsz - ph->p_filesz);
}
printf("Loaded PT_LOAD[%zu]: off 0x%08" PRIx32 " -> image[0x%08" PRIx64 "] ",
i, ph->p_offset, image_off);
print_program_flags(ph->p_flags);
printf(" filesz 0x%08" PRIx32 " memsz 0x%08" PRIx32 "\n", ph->p_filesz, ph->p_memsz);
}
uint64_t entry_offset_in_image = eh->e_entry - min_vaddr;
printf("\n");
printf("Entry in image buffer: image[0x%08" PRIx64 "]\n", entry_offset_in_image);
LoadedImage result = {
.image = image,
.image_size = image_size,
.min_vaddr = min_vaddr,
.max_vaddr = max_vaddr,
.entry_vaddr = eh->e_entry,
.entry_offset_in_image = entry_offset_in_image,
.machine = eh->e_machine,
.type = eh->e_type,
.elf_class = ELFCLASS32,
};
return result;
}
效果:
./mini_loader /home/iotsec-zone/Desktop/ELF/first-arm
File: /home/iotsec-zone/Desktop/ELF/first-arm
ELF32 loader plan:
machine ARM
image range [0x00000000, 0x0001100c)
image size 0x0001100c
entry vaddr 0x000005c1
Loaded PT_LOAD[3]: off 0x00000000 -> image[0x00000000] R-E filesz 0x000009f8 memsz 0x000009f8
Loaded PT_LOAD[4]: off 0x00000ea8 -> image[0x00010ea8] RW- filesz 0x00000160 memsz 0x00000164
Entry in image buffer: image[0x000005c1]
Summary:
class ELF32
machine ARM
min vaddr 0x00000000
max vaddr 0x0001100c
entry vaddr 0x000005c1
entry image 0x000005c1
总结它的本质就是,根据 Program Header 中的 PT_LOAD 信息,把 ELF 从“文件视图”变成“一块已经按虚拟地址布局好的模拟内存镜像”。
Mini Linker
mini_linker 是在 mini_loader基础上,在 PT_LOAD 已经装入模拟内存的前提下,继续解析 PT_DYNAMIC,收集动态链接信息,并对最基础的一类重定位 R_*_RELATIVE 做实际修补。
库函数以及结构体
#include <elf.h>
#include <errno.h>
#include <inttypes.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
uint8_t *image;
uint64_t image_size;
uint64_t min_vaddr;
uint64_t max_vaddr;
uint64_t simulated_base;
uint16_t machine;
int elf_class;
} RuntimeImage;
typedef struct {
uint64_t rel;
uint64_t relsz;
uint64_t relent;
uint64_t rela;
uint64_t relasz;
uint64_t relaent;
uint64_t jmprel;
uint64_t pltrelsz;
uint64_t symtab;
uint64_t strtab;
uint64_t strsz;
uint64_t soname;
uint64_t needed_offsets[MAX_NEEDED_LIBS];
size_t needed_count;
uint64_t relcount;
uint64_t pltrel_type;
} DynamicInfo;
思路框架
先复用 mini_loader 的装载逻辑,把所有 PT_LOAD 段装进一块连续的 image 中;然后从Program Header 里找到 PT_DYNAMIC 和PT_INTERP,前者提供动态链接所需的各种表地址和大小,后者给出运行时解释器路径;接着把这些动态信息整理进 DynamicInfo,建立“虚拟地址 -> image 指针”的转换关系;最后遍历重定位表(REL 或 RELA),筛选当前架构下R_RELATIVE,按照模拟基址 simulated_base把目标位置修补成运行时应有的地址。同样的为了更好演示链接器的工作过程,我会把解释器、依赖库、动态符号表、字符串表、重定位表和修补结果打印出来。
源码
主函数的框架和前两个工具保持一致:先读文件、检查 ELF 魔数和大小端,再按 EI_CLASS 分流到 32 位或 64 位逻辑。不同的是,这里在load32() 之后把 ELF 变成 image ,继续进入动态信息收集和重定位处理阶段。
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "usage: %s <elf-file>\n", argv[0]);
return 1;
}
Buffer buf = read_file(argv[1]);
if (!range_ok(buf.size, 0, EI_NIDENT)) {
free(buf.data);
fail("file too small");
}
if (memcmp(buf.data, ELFMAG, SELFMAG) != 0) {
free(buf.data);
fail("not an ELF file");
}
if (buf.data[EI_DATA] != ELFDATA2LSB) {
free(buf.data);
fail("only little-endian ELF is supported for now");
}
printf("File: %s\n\n", buf.path);
if (buf.data[EI_CLASS] == ELFCLASS32) {
const Elf32_Ehdr *eh = NULL;
const Elf32_Phdr *phdrs = NULL;
RuntimeImage image = load32(&buf, &eh, &phdrs);
DynamicInfo dyn;
collect_dynamic32(&image, phdrs, eh->e_phnum, &dyn);
printf("Runtime linker view (ELF32):\n");
printf(" machine %s\n", machine_name(image.machine));
printf(" interpreter %s\n", interp_path32(&buf, phdrs, eh->e_phnum));
printf(" simulated base 0x%08" PRIx64 "\n", image.simulated_base);
printf(" image range [0x%08" PRIx64 ", 0x%08" PRIx64 ")\n", image.min_vaddr, image.max_vaddr);
if (dyn.soname != 0) {
printf(" soname %s\n", safe_dyn_string(&image, &dyn, dyn.soname));
}
print_needed_libraries(&image, &dyn);
printf(" dyn symtab 0x%08" PRIx64 "\n", dyn.symtab);
printf(" dyn strtab 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.strtab, dyn.strsz);
printf(" rel table 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.rel, dyn.relsz);
printf(" relcount 0x%08" PRIx64 "\n", dyn.relcount);
printf(" rela table 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.rela, dyn.relasz);
printf(" jmprel table 0x%08" PRIx64 " (size 0x%08" PRIx64 ", kind 0x%08" PRIx64 ")\n",
dyn.jmprel, dyn.pltrelsz, dyn.pltrel_type);
printf("\n");
apply_rel32(&image, &dyn);
apply_rela32(&image, &dyn);
print_jmprel32(&image, &dyn);
free(image.image);
} else if (buf.data[EI_CLASS] == ELFCLASS64) {
const Elf64_Ehdr *eh = NULL;
const Elf64_Phdr *phdrs = NULL;
RuntimeImage image = load64(&buf, &eh, &phdrs);
DynamicInfo dyn;
collect_dynamic64(&image, phdrs, eh->e_phnum, &dyn);
printf("Runtime linker view (ELF64):\n");
printf(" machine %s\n", machine_name(image.machine));
printf(" interpreter %s\n", interp_path64(&buf, phdrs, eh->e_phnum));
printf(" simulated base 0x%08" PRIx64 "\n", image.simulated_base);
printf(" image range [0x%08" PRIx64 ", 0x%08" PRIx64 ")\n", image.min_vaddr, image.max_vaddr);
if (dyn.soname != 0) {
printf(" soname %s\n", safe_dyn_string(&image, &dyn, dyn.soname));
}
print_needed_libraries(&image, &dyn);
printf(" dyn symtab 0x%08" PRIx64 "\n", dyn.symtab);
printf(" dyn strtab 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.strtab, dyn.strsz);
printf(" rel table 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.rel, dyn.relsz);
printf(" relcount 0x%08" PRIx64 "\n", dyn.relcount);
printf(" rela table 0x%08" PRIx64 " (size 0x%08" PRIx64 ")\n", dyn.rela, dyn.relasz);
printf(" jmprel table 0x%08" PRIx64 " (size 0x%08" PRIx64 ", kind 0x%08" PRIx64 ")\n",
dyn.jmprel, dyn.pltrelsz, dyn.pltrel_type);
printf("\n");
apply_rel64(&image, &dyn);
apply_rela64(&image, &dyn);
print_jmprel64(&image, &dyn);
free(image.image);
} else {
free(buf.data);
fail("unknown ELF class");
}
free(buf.data);
return 0;
}
再通过collect_dynamic32() / collect_dynamic64() 从 PT_DYNAMIC 中提取动态段信息,得到动态符号表、动态字符串表、普通重定位表和 PLT重定位表的位置;
static void collect_dynamic32(const RuntimeImage *image, const Elf32_Phdr *phdrs, size_t phnum, DynamicInfo *dyn) {
memset(dyn, 0, sizeof(*dyn));
for (size_t i = 0; i < phnum; ++i) {
const Elf32_Phdr *ph = &phdrs[i];
if (ph->p_type != PT_DYNAMIC) {
continue;
}
const Elf32_Dyn *entries = (const Elf32_Dyn *)image_ptr_const(image, ph->p_vaddr, ph->p_memsz);
if (entries == NULL) {
fail("PT_DYNAMIC outside loaded image");
}
size_t count = ph->p_memsz / sizeof(Elf32_Dyn);
for (size_t j = 0; j < count; ++j) {
switch (entries[j].d_tag) {
case DT_REL: dyn->rel = entries[j].d_un.d_ptr; break;
case DT_RELSZ: dyn->relsz = entries[j].d_un.d_val; break;
case DT_RELENT: dyn->relent = entries[j].d_un.d_val; break;
case DT_RELA: dyn->rela = entries[j].d_un.d_ptr; break;
case DT_RELASZ: dyn->relasz = entries[j].d_un.d_val; break;
case DT_RELAENT: dyn->relaent = entries[j].d_un.d_val; break;
case DT_JMPREL: dyn->jmprel = entries[j].d_un.d_ptr; break;
case DT_PLTRELSZ: dyn->pltrelsz = entries[j].d_un.d_val; break;
case DT_PLTREL: dyn->pltrel_type = entries[j].d_un.d_val; break;
case DT_SYMTAB: dyn->symtab = entries[j].d_un.d_ptr; break;
case DT_STRTAB: dyn->strtab = entries[j].d_un.d_ptr; break;
case DT_STRSZ: dyn->strsz = entries[j].d_un.d_val; break;
case DT_NEEDED:
if (dyn->needed_count < MAX_NEEDED_LIBS) {
dyn->needed_offsets[dyn->needed_count++] = entries[j].d_un.d_val;
}
break;
case DT_SONAME: dyn->soname = entries[j].d_un.d_val; break;
case DT_RELCOUNT: dyn->relcount = entries[j].d_un.d_val; break;
case DT_NULL: return;
default: break;
}
}
return;
}
}
然后通过image_ptr() 这一类辅助逻辑,把这些虚拟地址映射到 image 中的真实指针;
static bool image_range_ok(const RuntimeImage *image, uint64_t vaddr, uint64_t size) {
if (vaddr < image->min_vaddr) {
return false;
}
if (vaddr > image->max_vaddr) {
return false;
}
return size <= image->max_vaddr - vaddr;
}
static uint8_t *image_ptr(RuntimeImage *image, uint64_t vaddr, uint64_t size) {
if (!image_range_ok(image, vaddr, size)) {
return NULL;
}
return image->image + (size_t)(vaddr - image->min_vaddr);
}
static const uint8_t *image_ptr_const(const RuntimeImage *image, uint64_t vaddr, uint64_t size) {
if (!image_range_ok(image, vaddr, size)) {
return NULL;
}
return image->image + (size_t)(vaddr - image->min_vaddr);
}
最后apply_rel32()、apply_rela32()、apply_rel64()、apply_rela64() 遍历 relocation(重定位项),识别当前架构的 R__RELATIVE,并把simulated_base + addend 或等价结果写回目标地址,模拟“程序装入后由runtime linker 把地址修正正确”的过程。
static void apply_rel32(RuntimeImage *image, const DynamicInfo *dyn) {
if (dyn->rel == 0 || dyn->relsz == 0) {
printf("REL table: not present\n");
return;
}
if (dyn->relent != 0 && dyn->relent != sizeof(Elf32_Rel)) {
fail("unexpected DT_RELENT");
}
const Elf32_Rel *rels = (const Elf32_Rel *)image_ptr_const(image, dyn->rel, dyn->relsz);
if (rels == NULL) {
fail("DT_REL outside loaded image");
}
uint32_t rel_type = relative_type32(image->machine);
size_t count = dyn->relsz / sizeof(Elf32_Rel);
size_t applied = 0;
size_t skipped = 0;
for (size_t i = 0; i < count; ++i) {
uint32_t type = ELF32_R_TYPE(rels[i].r_info);
if (type != rel_type) {
skipped++;
continue;
}
uint32_t *where = (uint32_t *)image_ptr(image, rels[i].r_offset, sizeof(uint32_t));
if (where == NULL) {
fail("REL target outside loaded image");
}
uint32_t original = *where;
*where = (uint32_t)(image->simulated_base + original);
if (applied < 5) {
printf(" REL[%zu] off 0x%08" PRIx32 " relative: 0x%08" PRIx32 " -> 0x%08" PRIx32 "\n",
i, rels[i].r_offset, original, *where);
}
applied++;
}
printf("REL table: applied %zu relative relocations, skipped %zu others\n", applied, skipped);
}
static void apply_rela32(RuntimeImage *image, const DynamicInfo *dyn) {
if (dyn->rela == 0 || dyn->relasz == 0) {
printf("RELA table: not present\n");
return;
}
if (dyn->relaent != 0 && dyn->relaent != sizeof(Elf32_Rela)) {
fail("unexpected DT_RELAENT");
}
const Elf32_Rela *rels = (const Elf32_Rela *)image_ptr_const(image, dyn->rela, dyn->relasz);
if (rels == NULL) {
fail("DT_RELA outside loaded image");
}
uint32_t rel_type = relative_type32(image->machine);
size_t count = dyn->relasz / sizeof(Elf32_Rela);
size_t applied = 0;
size_t skipped = 0;
for (size_t i = 0; i < count; ++i) {
uint32_t type = ELF32_R_TYPE(rels[i].r_info);
if (type != rel_type) {
skipped++;
continue;
}
uint32_t *where = (uint32_t *)image_ptr(image, rels[i].r_offset, sizeof(uint32_t));
if (where == NULL) {
fail("RELA target outside loaded image");
}
*where = (uint32_t)(image->simulated_base + (uint32_t)rels[i].r_addend);
if (applied < 5) {
printf(" RELA[%zu] off 0x%08" PRIx32 " addend 0x%08" PRIx32 " -> 0x%08" PRIx32 "\n",
i, rels[i].r_offset, (uint32_t)rels[i].r_addend, *where);
}
applied++;
}
printf("RELA table: applied %zu relative relocations, skipped %zu others\n", applied, skipped);
}
最小linker主要沿着PT_DYNAMIC -> relocation -> 地址修补 这条主要框架看。
关键代码示意
下面这类逻辑最能体现 Mini Linker 的核心思想:先收集动态信息,再对相对重定位做修补。
collect_dynamic32(&image, phdrs, eh->e_phnum, &dyn);
apply_rel32(&image, &dyn);
apply_rela32(&image, &dyn);
print_jmprel32(&image, &dyn);
如果是 REL 类型重定位,代码通常会:
- 找到 relocation 表在 image 中的位置
- 遍历每个 Elf32_Rel
- 从 r_info 中取出 relocation type
- 判断是否为当前机器对应的 R_*_RELATIVE
- 找到 r_offset 对应的目标地址
- 把基址相关的值写回去
如果是 RELA 类型重定位,则逻辑类似,只是 addend(附加值)直接来自 r_addend。
效果:
./mini_linker /home/iotsec-zone/Desktop/ELF/first-arm
File: /home/iotsec-zone/Desktop/ELF/first-arm
Runtime linker view (ELF32):
machine ARM
interpreter /lib/ld-linux-armhf.so.3
simulated base 0x10000000
image range [0x00000000, 0x0001100c)
needed libs
[0] libc.so.6
dyn symtab 0x000001cc
dyn strtab 0x000002fc (size 0x000000e3)
rel table 0x00000448 (size 0x00000040)
relcount 0x00000004
rela table 0x00000000 (size 0x00000000)
jmprel table 0x00000488 (size 0x00000070, kind 0x00000011)
REL[0] off 0x00010ea8 relative: 0x000006b9 -> 0x100006b9
REL[1] off 0x00010eac relative: 0x00000679 -> 0x10000679
REL[2] off 0x00010ff8 relative: 0x00000775 -> 0x10000775
REL[3] off 0x00011004 relative: 0x00011004 -> 0x10011004
REL table: applied 4 relative relocations, skipped 4 others
RELA table: not present
PLT relocations:
[ 0] off 0x00010fb4 type 22 sym 3 __libc_start_main
[ 1] off 0x00010fb8 type 22 sym 4 __cxa_finalize
[ 2] off 0x00010fbc type 22 sym 6 printf
[ 3] off 0x00010fc0 type 22 sym 7 fopen
[ 4] off 0x00010fc4 type 22 sym 8 fgets
[ 5] off 0x00010fc8 type 22 sym 9 perror
[ 6] off 0x00010fcc type 22 sym 10 strcpy
[ 7] off 0x00010fd0 type 22 sym 11 puts
[ 8] off 0x00010fd4 type 22 sym 12 __gmon_start__
[ 9] off 0x00010fd8 type 22 sym 13 fprintf
[10] off 0x00010fdc type 22 sym 14 __isoc99_sscanf
[11] off 0x00010fe0 type 22 sym 15 fclose
[12] off 0x00010fe4 type 22 sym 16 __isoc99_scanf
[13] off 0x00010fe8 type 22 sym 18 abort
总结它的本质就是:在 mini_loader 已经完成“文件视图 -> 模拟内存视图”的前提下,再根据 PT_DYNAMIC 提供的动态链接信息,把 ELF 从“已经装进内存但地址还没完全就绪的映像”,推进“经过最小重定位修补的运行时视图”。也就是说,这个 Mini Linker 想教会读者的核心不是完整链接实现,而是先理解 runtime linker 最本质的职责:根据动态信息找到需要修补的位置,并把程序运行时真正需要的地址写进去。


