
写在前面
本文是afl-fuzz的源码解读的第二部分,在前一篇中我们进行了 afl 关于初始配置方面的内容,今天这篇将对接下来的 fuzz 执行阶段进行介绍。
afl-fuzz-2
1. 函数源码分析 - fuzz 执行阶段
备注
代码中会有一些 APPLE 平台的逻辑处理和功能实现,但文章中将只分析 Linux 平台的逻辑实现,APPLE 的基本一致,没有太大差别。
1. 第一次 Fuzz
1. 获取当前时间、判断是否处于qemu模式
首先调用 get_cur_time() 函数来获取当前时间作为 start_time ,然后使用一个 if 来判断是否处于 qemu_mode,如果是在 qemu_mode 下,则需要调用 get_qemu_argv() 函数来获取 qemu 模式下的特定参数。
2. perform_dry_run
该函数是 afl-fuzz 中的一个关键函数,它会执行 input 文件夹下的预先准备的所有的测试用例,生成初始化的 qeueue 和 bitmap,只对初始输入执行一次。目的主要是检查是否按照预期工作。我们首先给一个 UML 的时序图来看下函数的整体的执行过程:
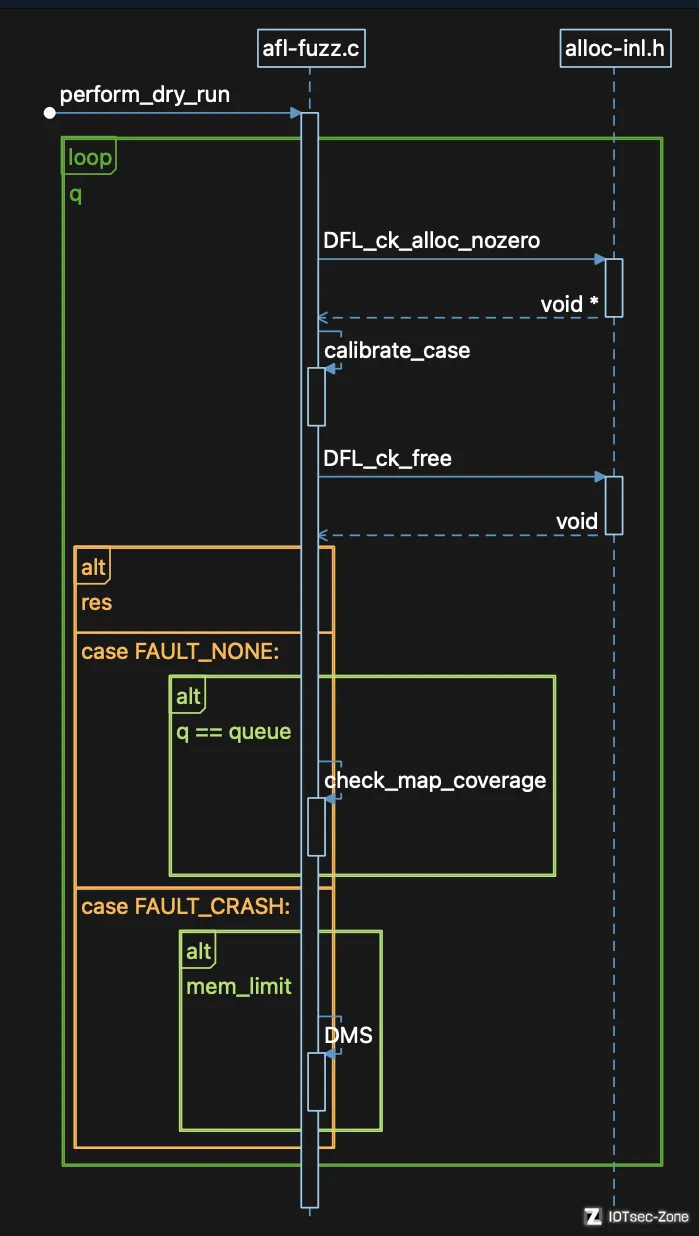
函数的整体是在个一个 while 的循环中,这个循环主要是便利所有的 queue,然后再根据不同的情况来设置不同的 case 进行处理。接下来看下函数的详细过程:
/* Perform dry run of all test cases to confirm that the app is working as
expected. This is done only for the initial inputs, and only once. */
static void perform_dry_run(char** argv) {
struct queue_entry* q = queue; // 创建queue_entry结构体
u32 cal_failures = 0;
u8* skip_crashes = getenv("AFL_SKIP_CRASHES"); // 读取环境变量 AFL_SKIP_CRASHES
while (q) { // 遍历队列
u8* use_mem;
u8 res;
s32 fd;
u8* fn = strrchr(q->fname, '/') + 1;
ACTF("Attempting dry run with '%s'...", fn);
fd = open(q->fname, O_RDONLY);
if (fd < 0) PFATAL("Unable to open '%s'", q->fname);
use_mem = ck_alloc_nozero(q->len);
if (read(fd, use_mem, q->len) != q->len)
FATAL("Short read from '%s'", q->fname); // 打开q->fname,读取到分配的内存中
close(fd);
res = calibrate_case(argv, q, use_mem, 0, 1); // 调用函数calibrate_case校准测试用例
ck_free(use_mem);
if (stop_soon) return;
if (res == crash_mode || res == FAULT_NOBITS)
SAYF(cGRA " len = %u, map size = %u, exec speed = %llu us\n" cRST,
q->len, q->bitmap_size, q->exec_us);
switch (res) { // 判断res的值
case FAULT_NONE:
if (q == queue) check_map_coverage(); // 如果为头结点,调用check_map_coverage评估覆盖率
if (crash_mode) FATAL("Test case '%s' does *NOT* crash", fn); // 抛出异常
break;
case FAULT_TMOUT:
if (timeout_given) { // 指定了 -t 选项
/* The -t nn+ syntax in the command line sets timeout_given to '2' and
instructs afl-fuzz to tolerate but skip queue entries that time
out. */
if (timeout_given > 1) {
WARNF("Test case results in a timeout (skipping)");
q->cal_failed = CAL_CHANCES;
cal_failures++;
break;
}
SAYF(... ...);
FATAL("Test case '%s' results in a timeout", fn);
} else {
SAYF(... ...);
FATAL("Test case '%s' results in a timeout", fn);
}
case FAULT_CRASH:
if (crash_mode) break;
if (skip_crashes) {
WARNF("Test case results in a crash (skipping)");
q->cal_failed = CAL_CHANCES;
cal_failures++;
break;
}
if (mem_limit) { // 建议增加内存
SAYF(... ...);
} else {
SAYF(... ...);
}
FATAL("Test case '%s' results in a crash", fn);
case FAULT_ERROR:
FATAL("Unable to execute target application ('%s')", argv[0]);
case FAULT_NOINST: // 测试用例运行没有路径信息
FATAL("No instrumentation detected");
case FAULT_NOBITS: // 没有出现新路径,判定为无效路径
useless_at_start++;
if (!in_bitmap && !shuffle_queue)
WARNF("No new instrumentation output, test case may be useless.");
break;
}
if (q->var_behavior) WARNF("Instrumentation output varies across runs.");
q = q->next; // 读取下一个queue
}
if (cal_failures) {
if (cal_failures == queued_paths)
FATAL("All test cases time out%s, giving up!",
skip_crashes ? " or crash" : "");
WARNF("Skipped %u test cases (%0.02f%%) due to timeouts%s.", cal_failures,
((double)cal_failures) * 100 / queued_paths,
skip_crashes ? " or crashes" : "");
if (cal_failures * 5 > queued_paths)
WARNF(cLRD "High percentage of rejected test cases, check settings!");
}
OKF("All test cases processed.");
}
- 读取环境变量
AFL_SKIP_CRASHES到skip_crashes变量,并设置cal_failures = 0; - 进入
while循环,开始读取 queue:- 打开
q->frame,读取到ck_alloc_nozero分配的内存use_mem中; - 调用
calibrate_case(argv, q, use_mem, 0, 1)来校准测试用例,返回值保存在res变量(后续还会详细介绍该函数); - 如果
stop_soon设置为1,直接返回; - 判断
res的值是否为crash_mode或FAULT_NOBITS,就打印SAYF("len = %u, map size = %u, exec speed = %llu us\n", q->len, q->bitmap_size, q->exec_us); - 进入一个
switch,来对res的各种值进行不同的处理,主要是 res 中会包含不同的错误,该 switch 就是对不同的错误情况进行不同的处理:- case FAULT_NONE:
- 如果
q是queue的头节点,也就是第一个测试用例,则调用check_map_coverage函数来评估 map coverage- 函数会计数
trace_bits发现的路径数量,如果小于100则直接返回; - 如果在
trace_bits的数组的后半部分存在有效值则直接返回; - 给出 warning:
WARNF("Recompile binary with newer version of afl to improve coverage!")
- 函数会计数
- 如果是
crash_mode,则直接抛出异常,FATAL("Test case '%s' does *NOT* crash", fn)
- 如果
- case FAULT_TMOUT:
- 如果设置了
timeout_given,也就是通过-t选项指定了超时时间,则timeout_given的值为2,抛出警告WARNF("Test case results in a timeout (skipping)"),并设置q->cal_failed = CAL_CHANCES,然后cal_failures++,表示失败 + 1; - 如果没有设置
-t参数或者timeout_given的值为0,那么输出对应的描述信息,并最终抛出错误FATAL("Test case '%s' results in a timeout", fn)
- 如果设置了
- case FAULT_CRASH:
- 如果
crash_mode有值,则直接跳出while循环;如果设置了skip_crashes也是直接 break 循环; - 如果设置了
mem_limit,则给出可能需要增加内存的建议信息; - 不管有没有设置
mem_limit,都会抛出异常FATAL("Test case '%s' results in a crash", fn)
- 如果
- case FAULT_ERROR:抛出异常,无法执行目标程序
- case FAULT_NOINST:测试用例没有出现任何路径信息,抛出没有检测到插桩的异常;
- case FAULT_NOBITS:测试用例出现路径信息,但是没有出现新路径,抛出警告
WARNF("No new instrumentation output, test case may be useless."),判定为一个无效路径,useless_at_start计数器 +1;
- case FAULT_NONE:
- 如果
q->var_behavior成立,说明多次运行,在同样的输入条件下,出现了不同的覆盖信息,抛出警告WARNF("Instrumentation output varies across runs.") - 继续读取下一个queue,直到所有的测试用例执行结束。
- 打开
文件给出了各种错误的默认错误代码:
/* Execution status fault codes */
enum {
/* 00 */ FAULT_NONE,
/* 01 */ FAULT_TMOUT,
/* 02 */ FAULT_CRASH,
/* 03 */ FAULT_ERROR,
/* 04 */ FAULT_NOINST,
/* 05 */ FAULT_NOBITS
};
在没有进行修改的情况下,就按照默认值进行处理。
3. calibrate_case
该函数主要用于新测试用例的校准,在处理输入目录时执行,并在发现新路径时,评估新发现的测试用例是否可变。函数在多个位置都被调用,它会初始化并启动 fork server,多次运行测试用例,并用 update_bitmap_score 来进行初始的byte排序。我们还是先给一个 UML 时序图来整体看函数的执行流程:
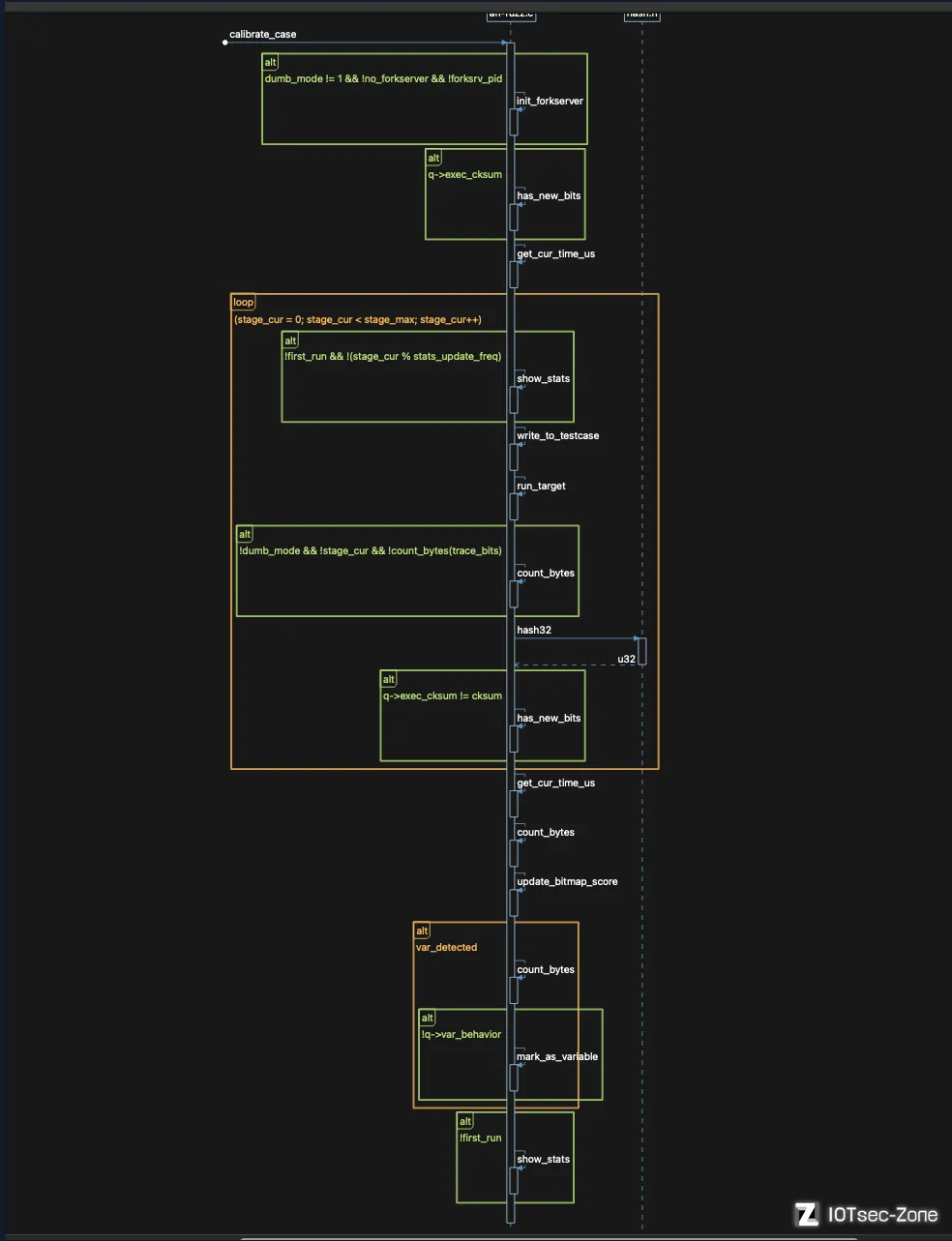
可以看到函数完成了大部分的测试用例的运行以及bitmap的计算等等工作,接下来通过源码来看下它的详细实现:
* Calibrate a new test case. This is done when processing the input directory
to warn about flaky or otherwise problematic test cases early on; and when
new paths are discovered to detect variable behavior and so on. */
static u8 calibrate_case(char** argv, struct queue_entry* q, u8* use_mem,
u32 handicap, u8 from_queue) {
static u8 first_trace[MAP_SIZE]; // 创建 firts_trace[MAP_SIZE]
u8 fault = 0, new_bits = 0, var_detected = 0, hnb = 0,
first_run = (q->exec_cksum == 0); // 获取执行追踪结果,判断case是否为第一次运行,若为0则表示第一次运行,来自input文件夹
u64 start_us, stop_us;
s32 old_sc = stage_cur, old_sm = stage_max;
u32 use_tmout = exec_tmout;
u8* old_sn = stage_name; // 保存原有 stage_cur, stage_max, stage_name
/* Be a bit more generous about timeouts when resuming sessions, or when
trying to calibrate already-added finds. This helps avoid trouble due
to intermittent latency. */
if (!from_queue || resuming_fuzz)
// 如果from_queue为0(表示case不是来自queue)或者resuming_fuzz为1(表示处于resuming sessions)
use_tmout = MAX(exec_tmout + CAL_TMOUT_ADD,
exec_tmout * CAL_TMOUT_PERC / 100); // 提升 use_tmout 的值
q->cal_failed++;
stage_name = "calibration"; // 设置 stage_name
stage_max = fast_cal ? 3 : CAL_CYCLES; // 设置 stage_max,新测试用例的校准周期数
/* Make sure the fork server is up before we do anything, and let's not
count its spin-up time toward binary calibration. */
if (dumb_mode != 1 && !no_fork server && !forksrv_pid)
init_fork server(argv); // 没有运行在dumb_mode,没有禁用fork server,切forksrv_pid为0时,启动fork server
if (q->exec_cksum) { // 判断是否为新case(如果这个queue不是来自input文件夹)
memcpy(first_trace, trace_bits, MAP_SIZE);
hnb = has_new_bits(virgin_bits);
if (hnb > new_bits) new_bits = hnb;
}
start_us = get_cur_time_us();
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) { // 开始执行 calibration stage,总计执行 stage_max 轮
u32 cksum;
if (!first_run && !(stage_cur % stats_update_freq)) show_stats(); // queue不是来自input,第一轮calibration stage执行结束,刷新一次展示界面
write_to_testcase(use_mem, q->len);
fault = run_target(argv, use_tmout);
/* stop_soon is set by the handler for Ctrl+C. When it's pressed,
we want to bail out quickly. */
if (stop_soon || fault != crash_mode) goto abort_calibration;
if (!dumb_mode && !stage_cur && !count_bytes(trace_bits)) {
// 如果 calibration stage第一次运行,且不在dumb_mode,共享内存中没有任何路径
fault = FAULT_NOINST;
goto abort_calibration;
}
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
if (q->exec_cksum != cksum) {
hnb = has_new_bits(virgin_bits);
if (hnb > new_bits) new_bits = hnb;
if (q->exec_cksum) { // 不等于exec_cksum,表示第一次运行,或在相同参数下,每次执行,cksum不同,表示是一个路径可变的queue
u32 i;
for (i = 0; i < MAP_SIZE; i++) {
if (!var_bytes[i] && first_trace[i] != trace_bits[i]) {
// 从0到MAP_SIZE进行遍历, first_trace[i] != trace_bits[i],表示发现了可变queue
var_bytes[i] = 1;
stage_max = CAL_CYCLES_LONG;
}
}
var_detected = 1;
} else {
q->exec_cksum = cksum; // q->exec_cksum=0,表示第一次执行queue,则设置计算出来的本次执行的cksum
memcpy(first_trace, trace_bits, MAP_SIZE);
}
}
}
stop_us = get_cur_time_us();
total_cal_us += stop_us - start_us; // 保存所有轮次的总执行时间
total_cal_cycles += stage_max; // 保存总轮次
/* OK, let's collect some stats about the performance of this test case.
This is used for fuzzing air time calculations in calculate_score(). */
q->exec_us = (stop_us - start_us) / stage_max; // 单次执行时间的平均值
q->bitmap_size = count_bytes(trace_bits); // 最后一次执行所覆盖的路径数
q->handicap = handicap;
q->cal_failed = 0;
total_bitmap_size += q->bitmap_size; // 加上queue所覆盖的路径数
total_bitmap_entries++;
update_bitmap_score(q);
/* If this case didn't result in new output from the instrumentation, tell
parent. This is a non-critical problem, but something to warn the user
about. */
if (!dumb_mode && first_run && !fault && !new_bits) fault = FAULT_NOBITS;
abort_calibration:
if (new_bits == 2 && !q->has_new_cov) {
q->has_new_cov = 1;
queued_with_cov++;
}
/* Mark variable paths. */
if (var_detected) { // queue是可变路径
var_byte_count = count_bytes(var_bytes);
if (!q->var_behavior) {
mark_as_variable(q);
queued_variable++;
}
}
// 恢复之前的stage值
stage_name = old_sn;
stage_cur = old_sc;
stage_max = old_sm;
if (!first_run) show_stats();
return fault;
}
总结以上过程如下:
-
首先是几个变量的设置: 创建
first_trace[MAP_SIZE]、设置first_run = (q->exec_cksum == 0)(这里如果q->cksum = 0,表示这个test case是第一次执行,也就是它来自于 input 文件夹,所以就设置first_run的值为1)、保存原有的当前阶段stage_cur、阶段名称stage_name以及stage_max的值、设置use_tmout = exec_tmout -
如果
from_queue不为0或者resuming_fuzz值为1,表示test case 不是来自于 queue或者此时处于resuming session,use_tmout的值会被设置的更大一些; -
设置
stage_name的值为calibration,表示处于 calibration 阶段,然后根据fast_cal是否为1来设置stage_max的值,如果为1设置为3,如果不是1则设置为CAL_CYCLES(8)。这里的stage_max表示的是阶段要执行的最大次数。 -
如果当前不是以dumb mode运行,且
no_forkserver(禁用forkserver)为0,且forksrv_pid为0,则调用init_forkserver(argv)启动 fork server; -
如果
q->exec_cksum的值为1,表示test case不是第一次执行,则拷贝trace_bits到first_trace中,然后调用has_new_bits(virgin_bits)来计算值,如果这个值大于new_bits,则赋值给new_bits。 -
get_cur_time_us()获取开始时间,然后进入 for 循环,开始循环执行 calibration stage,执行的次数为stage_max:-
如果
first_run为0,则queue不是来自input文件夹,而是评估新 test case,且第一轮执行结束时,刷新一次展示界面show_details(),来展示这次执行的结果; -
调用
write_to_testcase(use_mem, q->len)将从q->frame中读取的内容写入到.cur_input中; -
调用
run_target(argv, use_tmout)来执行目标程序,并返回执行的状态信息; -
如果是 calibration stage 的第一次运行,并且不处于 dumb 模式,并且共享内存中没有任何的路径,则设置
fault为FAULT_NOINST,然后跳转到abort_calibration处; -
计算
hash32(trace_bits, MAP_SIZE, HASH_CONST)保存到cksum变量。然后对比q->exec_cksum和cksum的值,不想等表示这是第一次运行,或者在相同参数下,每次执行的 cksum 不同表示是一个路径可变的 queue,则-
设置
hnb = has_new_bits(virgin_bits),然后根据大小赋值给new_bits; -
如果
q->exec_cksum的值不为0,表示需要判断是否是可变路径的queue:- 使用 for 循环遍历
MAP_SIZE,如果frist_trace[i] != trace_bits[i]表示发现了可变路径的 queue,且var_bytes为空的话,就将该字节设置为 1,并将stage_max设置为CAL_CYCLES_LONG; - 设置
var_detected = 1;
- 使用 for 循环遍历
-
如果
q->exec_cksum的值为0,表示这是第一次执行这个 queue,会设置q->exec_cksum的值为之前计算出来的cksum,并拷贝trace_bits到first_trace中。
-
-
-
再调用
get_cur_time_us()获取一个结束时间,然后计算total_cal_us += stop_us - start_us,这也就是所有轮的总的执行时间,并将总的执行轮次加到total_cal_cycles中; -
收集一些 test case 执行的性能数据,分别是
- 单次执行时间
q->exec_us - 路径数
q->bitmap_size,这里计算的是最后一次执行所覆盖的路径数 q->handicapq->cal_failed设置为0total_bitmap_size就是再加上q->bitmap_sizetotal_bitmap_entries++
- 单次执行时间
-
调用
update_bitmap_score()函数对测试用例的每个byte进行排序,用一个top_rate[]维护最佳入口; -
如果fault为
FAULT_NONE,且该queue是第一次执行,且不属于dumb_mode,而且new_bits为0,代表在这个样例所有轮次的执行里,都没有发现任何新路径和出现异常,设置fault为FAULT_NOBITS -
最后是
abort_calibration的处理。
总结:calibratecase函数到此为止,该函数主要用途是init_fork server;将testcase运行多次;用update_bitmap_score进行初始的byte排序。
4. init_forkserver
AFL的fork server机制避免了多次执行 execve() 函数的多次调用,只需要调用一次然后通过管道发送命令即可。该函数主要用于启动APP和它的fork server。
EXP_ST void init_fork server(char** argv) {
static struct itimerval it;
int st_pipe[2], ctl_pipe[2];
int status;
s32 rlen;
ACTF("Spinning up the fork server...");
if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed");
// 检查 st_pipe 和ctl_pipe,在父子进程间进行管道通信,一个用于传递状态,一个用于传递命令
forksrv_pid = fork();
// fork进程出一个子进程
// 如果fork成功,则现在有父子两个进程
// 此时的父进程为fuzzer,子进程则为目标程序进程,也是将来的fork server
if (forksrv_pid < 0) PFATAL("fork() failed"); // fork失败
// 子进程和父进程都会向下执行,通过pid来使父子进程执行不同的代码
if (!forksrv_pid) { // 子进程执行
struct rlimit r;
/* 中间省略针对OpenBSD的特殊处理 */
... ...
/* Isolate the process and configure standard descriptors. If out_file is
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
// 创建守护进程
setsid();
// 重定向文件描述符1和2到dev_null_fd
dup2(dev_null_fd, 1);
dup2(dev_null_fd, 2);
// 如果指定了out_file,则文件描述符0重定向到dev_null_fd,否则重定向到out_fd
if (out_file) {
dup2(dev_null_fd, 0);
} else {
dup2(out_fd, 0);
close(out_fd);
}
/* Set up control and status pipes, close the unneeded original fds. */
// 设置控制和状态管道,关闭不需要的一些文件描述符
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
close(ctl_pipe[0]);
close(ctl_pipe[1]);
close(st_pipe[0]);
close(st_pipe[1]);
close(out_dir_fd);
close(dev_null_fd);
close(dev_urandom_fd);
close(fileno(plot_file));
/* This should improve performance a bit, since it stops the linker from
doing extra work post-fork(). */
// 如果没有设置延迟绑定,则进行设置,不使用缺省模式
if (!getenv("LD_BIND_LAZY")) setenv("LD_BIND_NOW", "1", 0);
/* Set sane defaults for ASAN if nothing else specified. */
// 设置环境变量ASAN_OPTIONS,配置ASAN相关
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
/* MSAN is tricky, because it doesn't support abort_on_error=1 at this
point. So, we do this in a very hacky way. */
// MSAN相关
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
"symbolize=0:"
"abort_on_error=1:"
"allocator_may_return_null=1:"
"msan_track_origins=0", 0);
/* 带参数执行目标程序,报错才返回
execv()会替换原有进程空间为目标程序,所以后续执行的都是目标程序。
第一个目标程序会进入__afl_maybe_log里的__afl_fork_wait_loop,并充当fork server。
在整个过程中,每次要fuzz一次目标程序,都会从这个fork server再fork出来一个子进程去fuzz。
因此可以看作是三段式:fuzzer -> fork server -> target子进程
*/
execv(target_path, argv);
/* Use a distinctive bitmap signature to tell the parent about execv()
falling through. */
// 告诉父进程执行失败,结束子进程
*(u32*)trace_bits = EXEC_FAIL_SIG;
exit(0);
}
/* Close the unneeded endpoints. */
close(ctl_pipe[0]);
close(st_pipe[1]);
fsrv_ctl_fd = ctl_pipe[1]; // 父进程只能发送命令
fsrv_st_fd = st_pipe[0]; // 父进程只能读取状态
/* Wait for the fork server to come up, but don't wait too long. */
// 在一定时间内等待fork server启动
it.it_value.tv_sec = ((exec_tmout * FORK_WAIT_MULT) / 1000);
it.it_value.tv_usec = ((exec_tmout * FORK_WAIT_MULT) % 1000) * 1000;
setitimer(ITIMER_REAL, &it, NULL);
rlen = read(fsrv_st_fd, &status, 4); // 从管道里读取4字节数据到status
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &it, NULL);
/* If we have a four-byte "hello" message from the server, we're all set.
Otherwise, try to figure out what went wrong. */
if (rlen == 4) { // 以读取的结果判断fork server是否成功启动
OKF("All right - fork server is up.");
return;
}
// 子进程启动失败的异常处理相关
if (child_timed_out)
FATAL("Timeout while initializing fork server (adjusting -t may help)");
if (waitpid(forksrv_pid, &status, 0) <= 0)
PFATAL("waitpid() failed");
... ...
}
我们结合fuzzer对该函数的调用来梳理完整的流程如下:
启动目标程序进程后,目标程序会运行一个fork server,fuzzer自身并不负责fork子进程,而是通过管道与fork server通信,由fork server来完成fork以及继续执行目标程序的操作。

对于fuzzer和目标程序之间的通信状态我们可以通过下图来梳理:
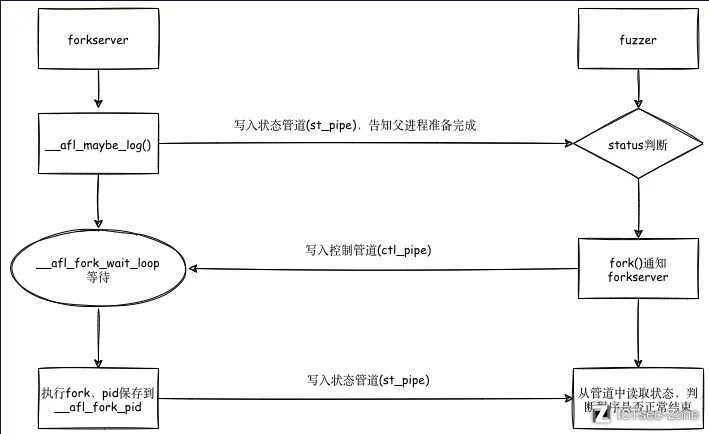
结合前面的插桩部分一起来看:
首先,afl-fuzz 会创建两个管道:状态管道和控制管道,然后执行目标程序。此时的目标程序的 main() 函数已经被插桩,程序控制流进入 __afl_maybe_log 中。如果fuzz是第一次执行,则此时的程序就成了fork server们之后的目标程序都由该fork server通过fork生成子进程来运行。fuzz进行过程中,fork server会一直执行fork操作,并将子进程的结束状态通过状态管道传递给 afl-fuzz。
5. has_new_bits
该函数主要用来检查有没有新路径产生或者某个路径的执行次数是否与之前不同,其内部实现并没有特别值得需要关注的点,而且其实现主要是字节数据的相关操作,大家可自行阅读源码即可。
6. run_target
该函数我们前面有简单介绍,主要是执行目标程序,并进行超时监控,最后会返回程序的状态信息,被调用程序会更新 trace_bits:
static u8 run_target(char** argv, u32 timeout) {
static struct itimerval it;
static u32 prev_timed_out = 0;
static u64 exec_ms = 0;
int status = 0;
u32 tb4;
child_timed_out = 0;
/* After this memset, trace_bits[] are effectively volatile, so we
must prevent any earlier operations from venturing into that
territory. */
memset(trace_bits, 0, MAP_SIZE); // 将trace_bits全部置0,清空共享内存
MEM_BARRIER();
/* If we're running in "dumb" mode, we can't rely on the fork server
logic compiled into the target program, so we will just keep calling
execve(). There is a bit of code duplication between here and
init_fork server(), but c'est la vie. */
if (dumb_mode == 1 || no_fork server) { // 如果是dumb_mode模式且没有fork server
child_pid = fork(); // 直接fork出一个子进程
if (child_pid < 0) PFATAL("fork() failed");
if (!child_pid) {
... ...
/* Isolate the process and configure standard descriptors. If out_file is
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
setsid();
dup2(dev_null_fd, 1);
dup2(dev_null_fd, 2);
if (out_file) {
dup2(dev_null_fd, 0);
} else {
dup2(out_fd, 0);
close(out_fd);
}
/* On Linux, would be faster to use O_CLOEXEC. Maybe TODO. */
close(dev_null_fd);
close(out_dir_fd);
close(dev_urandom_fd);
close(fileno(plot_file));
/* Set sane defaults for ASAN if nothing else specified. */
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
"symbolize=0:"
"msan_track_origins=0", 0);
execv(target_path, argv); // 让子进程execv执行目标程序
/* Use a distinctive bitmap value to tell the parent about execv()
falling through. */
*(u32*)trace_bits = EXEC_FAIL_SIG; // execv执行失败,写入 EXEC_FAIL_SIG
exit(0);
}
} else {
s32 res;
/* In non-dumb mode, we have the fork server up and running, so simply
tell it to have at it, and then read back PID. */
// 如果并不是处在dumb_mode模式,说明fork server已经启动了,我们只需要进行
// 控制管道的写和状态管道的读即可
if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if (child_pid <= 0) FATAL("Fork server is misbehaving (OOM?)");
}
/* Configure timeout, as requested by user, then wait for child to terminate. */
// 配置超时,等待子进程结束
it.it_value.tv_sec = (timeout / 1000);
it.it_value.tv_usec = (timeout % 1000) * 1000;
setitimer(ITIMER_REAL, &it, NULL);
/* The SIGALRM handler simply kills the child_pid and sets child_timed_out. */
if (dumb_mode == 1 || no_fork server) {
if (waitpid(child_pid, &status, 0) <= 0) PFATAL("waitpid() failed");
} else {
s32 res;
if ((res = read(fsrv_st_fd, &status, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to communicate with fork server (OOM?)");
}
}
if (!WIFSTOPPED(status)) child_pid = 0;
getitimer(ITIMER_REAL, &it);
exec_ms = (u64) timeout - (it.it_value.tv_sec * 1000 +
it.it_value.tv_usec / 1000); // 计算执行时间
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &it, NULL);
total_execs++;
/* Any subsequent operations on trace_bits must not be moved by the
compiler below this point. Past this location, trace_bits[] behave
very normally and do not have to be treated as volatile. */
MEM_BARRIER();
tb4 = *(u32*)trace_bits;
// 分别执行64和32位下的classify_counts,设置trace_bits所在的mem
#ifdef WORD_SIZE_64
classify_counts((u64*)trace_bits);
#else
classify_counts((u32*)trace_bits);
#endif /* ^WORD_SIZE_64 */
prev_timed_out = child_timed_out;
/* Report outcome to caller. */
if (WIFSIGNALED(status) && !stop_soon) {
kill_signal = WTERMSIG(status);
if (child_timed_out && kill_signal == SIGKILL) return FAULT_TMOUT;
return FAULT_CRASH;
}
/* A somewhat nasty hack for MSAN, which doesn't support abort_on_error and
must use a special exit code. */
if (uses_asan && WEXITSTATUS(status) == MSAN_ERROR) {
kill_signal = 0;
return FAULT_CRASH;
}
if ((dumb_mode == 1 || no_fork server) && tb4 == EXEC_FAIL_SIG)
return FAULT_ERROR;
/* It makes sense to account for the slowest units only if the testcase was run
under the user defined timeout. */
if (!(timeout > exec_tmout) && (slowest_exec_ms < exec_ms)) {
slowest_exec_ms = exec_ms;
}
return FAULT_NONE;
}
- 调用
memset(trace_bits, 0, MAP_SIZE)将共享内存全部置0; - 如果
dumb_mode == 1并且no_forkserver为1的话,则直接 fork 一个子进程出来,让子进程去执行目标程序,如果执行失败,则向trace_bits写入EXEC_FAIL_SIG; - 否则向控制管道写入
prev_timed_out的值,命令Fork server开始fork出一个子进程进行fuzz,然后从状态管道读取fork server返回的fork出的子进程的ID到child_pid - 设置计数器为 timeout,超时则kill掉子进程,并设置
child_time_out为1; - 计算目标程序执行的时间
exec_ms,并将total_execs这个执行次数计数器+1; - 等待目标程序执行结束,如果是dumb_mode,目标程序执行结束的状态码直接保存到status中,如果不是dumb_mode,则从状态管道中读取target执行结束的状态码。
- 然后是调用
classify_counts函数,32位和64位是情况而定; - 最后就是一些根据
status的值向调用者返回不同的结果。
该函数整体上并没有太大难度,主要就是调用目标程序去执行,然后搜集状态信息返回。
7. update_bitmap_score
当我们发现一个新路径时,需要对新路径进行一个判断,主要是看它是否包含最小的路径集合能遍历到所有bitmap中的位,并在之后的fuzz过程中聚焦在这些路径上。以上过程的第一步是为bitmap中的每个字节维护一个 top_rated[] 的列表,这里会计算究竟哪些位置是更“合适”的,该函数主要实现该过程。
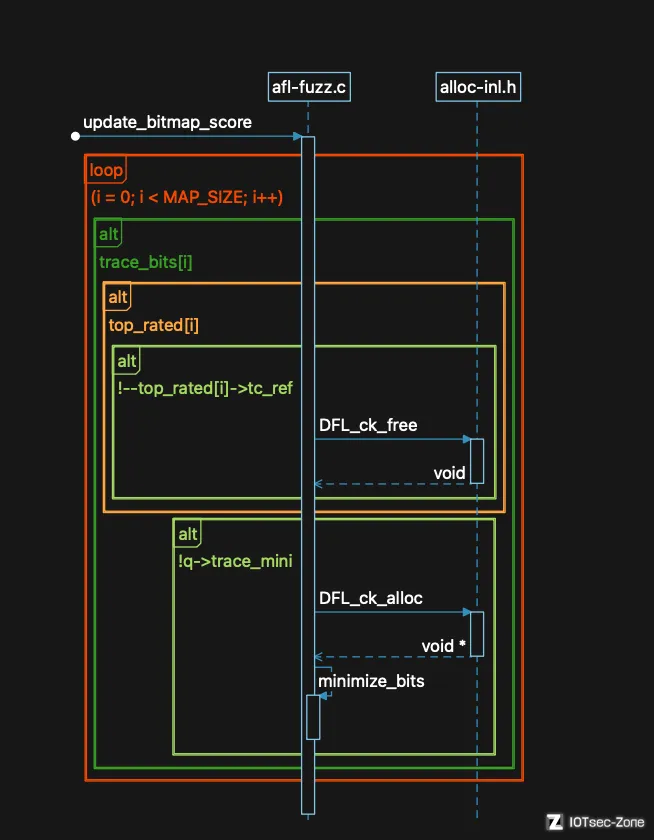
其整体也是在一个循环中,我们直接看源码即可:
static void update_bitmap_score(struct queue_entry* q) {
u32 i;
u64 fav_factor = q->exec_us * q->len;
// 首先计算case的fav_factor,计算方法是执行时间和样例大小的乘积
/* For every byte set in trace_bits[], see if there is a previous winner,
and how it compares to us. */
for (i = 0; i < MAP_SIZE; i++) // 遍历trace_bits数组
if (trace_bits[i]) { // 不为0,表示已经被覆盖到的路径
if (top_rated[i]) { // 检查top_rated是否存在
/* Faster-executing or smaller test cases are favored. */
if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue; // 判断哪个计算结果更小
// 如果top_rated[i]的更小,则代表它的更优,不做处理,继续遍历下一个路径;
// 如果q的更小,就执行以下代码:
/* Looks like we're going to win. Decrease ref count for the
previous winner, discard its trace_bits[] if necessary. */
if (!--top_rated[i]->tc_ref) {
ck_free(top_rated[i]->trace_mini);
top_rated[i]->trace_mini = 0;
}
}
/* Insert ourselves as the new winner. */
top_rated[i] = q; // 设置为当前case
q->tc_ref++;
if (!q->trace_mini) { // 为空
q->trace_mini = ck_alloc(MAP_SIZE >> 3);
minimize_bits(q->trace_mini, trace_bits);
}
score_changed = 1;
}
}
阶段总结
第一次 Fuzz 相关的主要函数基本上就介绍完了,我们没有进行全部覆盖,有一些函数大家自行阅读一下其逻辑即可,第一次 Fuzz 结束之后,我们就会进入到一个主循环中,主循环是我们进行的fuzz执行过程。
(强烈建议大家手动调试一下 AFL 的源码,观察上述各个流程中的各个阶段的数据,有助于大家更深入地理解。我们下期见。)



